


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Parallel computing makes use of multithreading, a hardware feature of CPUs (computer processing units) and GPUs (graphic processing units) that allows the OS (operating system) to send multiple self-contained sequences of instructions.

Parallel computing is a programming paradigm that differs from linear programming. It’s a powerful tool for optimizing certain background processes when programming videogames in engines like Unity, but videogame developers must take into consideration certain key aspects of it to avoid pitfalls and take advantage.
Parallel computing makes use of multithreading, a hardware feature of CPUs (computer processing units) and GPUs (graphic processing units) that allows the OS (operating system) to send multiple self-contained sequences of instructions called threads that are part of the same root process, and are executed asynchronously by the CPU and GPU. Basically, this computing paradigm divides algorithmic problems in smaller threads to be executed simultaneously.
An example of multithreading in Unity is the execution of the rendering process through various task threads vis-à-vis the same process executed in a single thread. This parallel execution of multiple threads that corresponds to a same root process lets developers distribute the workload through different tasks solvable simultaneously rather than linearly. It’s drastically different to send 50 tasks to be solved in a single thread than to send two threads of 25 tasks each, because it can reduce processing time, especially when programming videogames where processes have to be executed frame by frame. As we know, the faster those processes happen between frames, the more frames can be displayed per second, which results in smoother games.
Developers must always bear in mind the implications of asynchronicity; tasks executed in parallel will most likely always end execution at different times, and this can pose the following challenges.
Concurrency: because different tasks are executed in parallel, they can compete for the use of the same resources (for instance, the same memory block), and it can result in one task overwriting its outputs over the outputs of another task, and depending on the circumstances, the developer might not want this to happen. To avoid this concurrency, developers should reserve the resources that correspond to each task, so that they don’t compete over them and overwrite their respective outputs. An example of this is when the pathfinding of various artificial intelligence agents is programmed in parallel, and the fact that they might be using the same programming blocks is not taken into account. As a consequence, the algorithm could make the agents collide or superimpose on each other, a conduct developers don’t want them to have, because pathfinding tries to make artificial intelligence agents avoid obstacles, not the other way around.
Race conditions: parallel computing’s asynchronous nature forces developers to design an algorithm’s architecture in such a way as to avoid common errors, like thinking that the order of execution and results will be preserved as tasks are executed. It means that when a developer is designing an algorithm to execute threads in parallel, some tasks require the output of other tasks. If the algorithm is not designed in a way that each task matches in the right moment with the other tasks in execution, the algorithm could fail, resulting in a bug. A developer should wait until the end of every parallel task, and synchronize every task’s output with the next one’s point of execution, allowing the thread to finish calculating all the output needed by the algorithm to continue executing itself.
Below you can see four examples of parallel programming versus linear programming, in terms of execution time for both cases.
Calculation of a texture pixels, applying a mathematical function of an elliptical fall off:

Entry parameters
Texture size: 512x512
Ellipse parameters {A:0.5, B: 0.3}
Hardness: 0.8
The following code shows the programming of the parent class that will be used in all the examples:
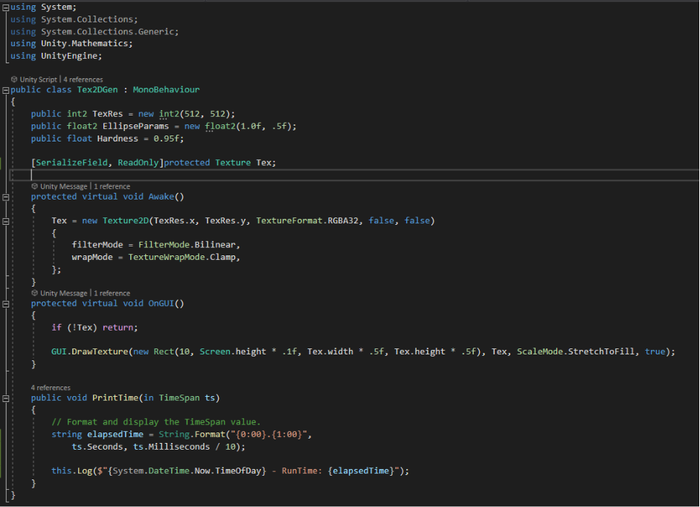
1. Linear execution using C#:
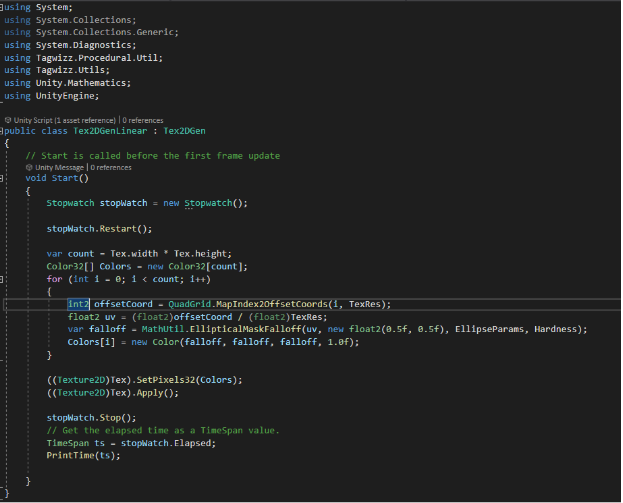
The following image shows the execution time by using linear execution in C#:
It’s important to note that the code is optimized regarding the memory allocation for the texture; more specifically, we used SerPixels rather than SerPixel, and we saved execution time by making only one information allocation for the texture, rather than one allocation every time a pixel is calculated.
We obtain an average time of execution of 0.13 second in linear programming. The time between processes tends to be constant.
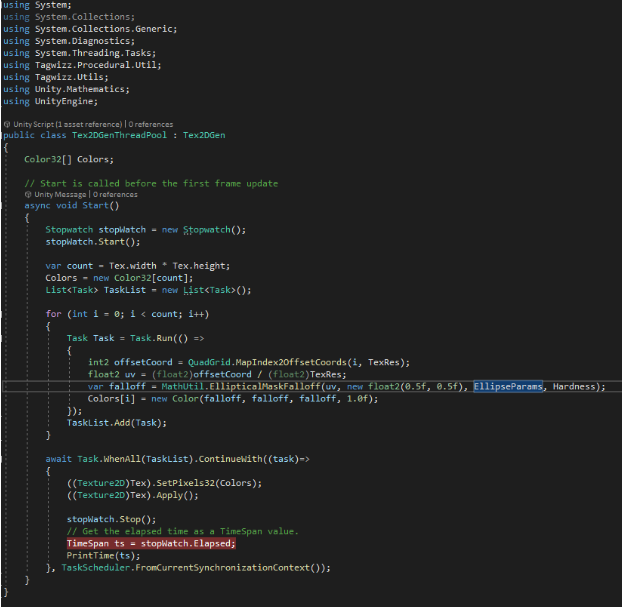
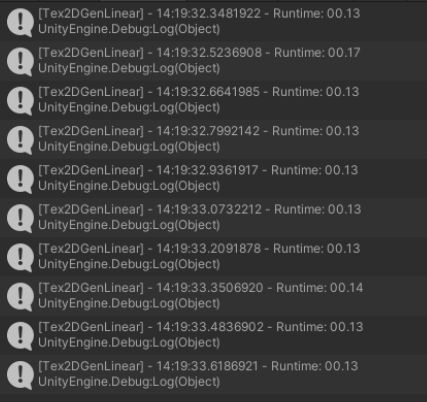
The following image shows the execution time of parallel execution using C# Task Threadpool:
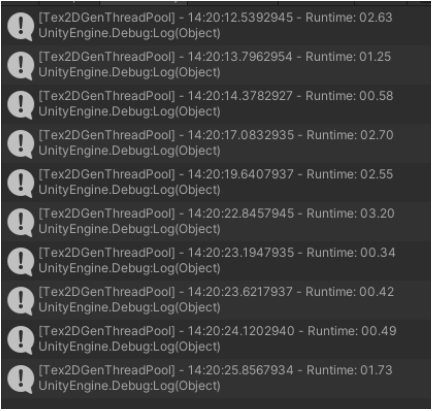
We obtain an average time of execution of 1.59 seconds. Also, the results are far from being consistent between launches.
Surprisingly, despite parallel programming, the execution time of each consecutive routine skyrocketed. This is because internally, threadpool allocates and reviews availability to be able to dispatch the process, which can result in bottlenecks. This can possibly be the reason for the loss of performance for tasks that require a high level of performance. In cases such as these, parallel programming is less optimal than linear programming due to the nature of implementation in C# Threadpool. Maybe it would be possible to have better results by programming our own threads system. However, that requires a lot of development time and language management at “low level”. Throwing a new processing thread is not “free”, because the OS needs to validate resources and assign processes. This produces a memory overhead that needs to be taken into account when designing parallel programming processes.
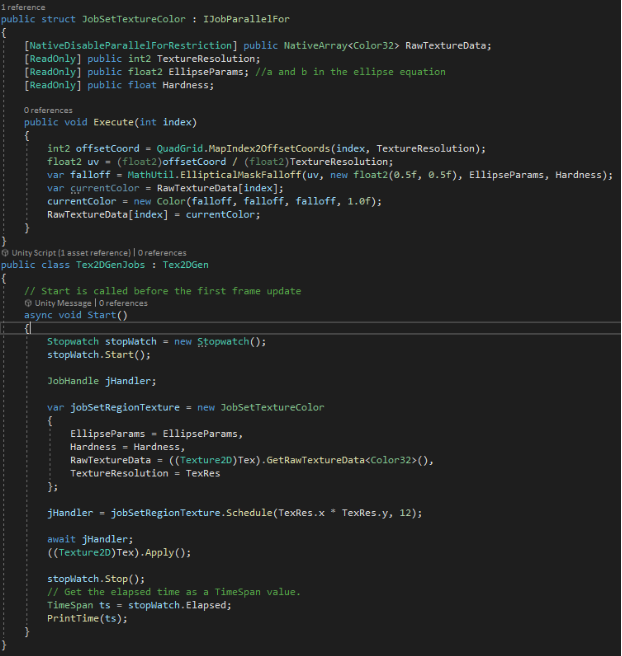
The following image shows the execution time of parallel execution using Unity Jobs system:
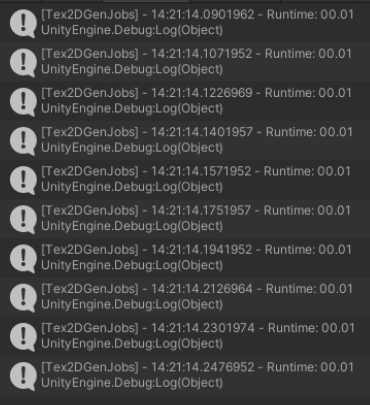
We obtain an average time of execution of 0.01 second. The time between each consecutive routine tends to be constant.
We can see a big difference between the execution time in Unity Jobs system (UJS) versus both C# Threadpool (CSTP) and linear execution. In the case of UJS versus CSTP, it is complicated to obtain an optimization factor in the order of execution speed, because CSTP times are very volatile. However, it is evident that it is almost always a hundred times faster. In the case between linear programming and UJS, it is evident that the speed increase factor for solutions is approximately 14 times faster.
UJS is a fairly powerful tool designed for high performance processes that execute in real time. It is truly superb what the Unity team achieved with this programming module.
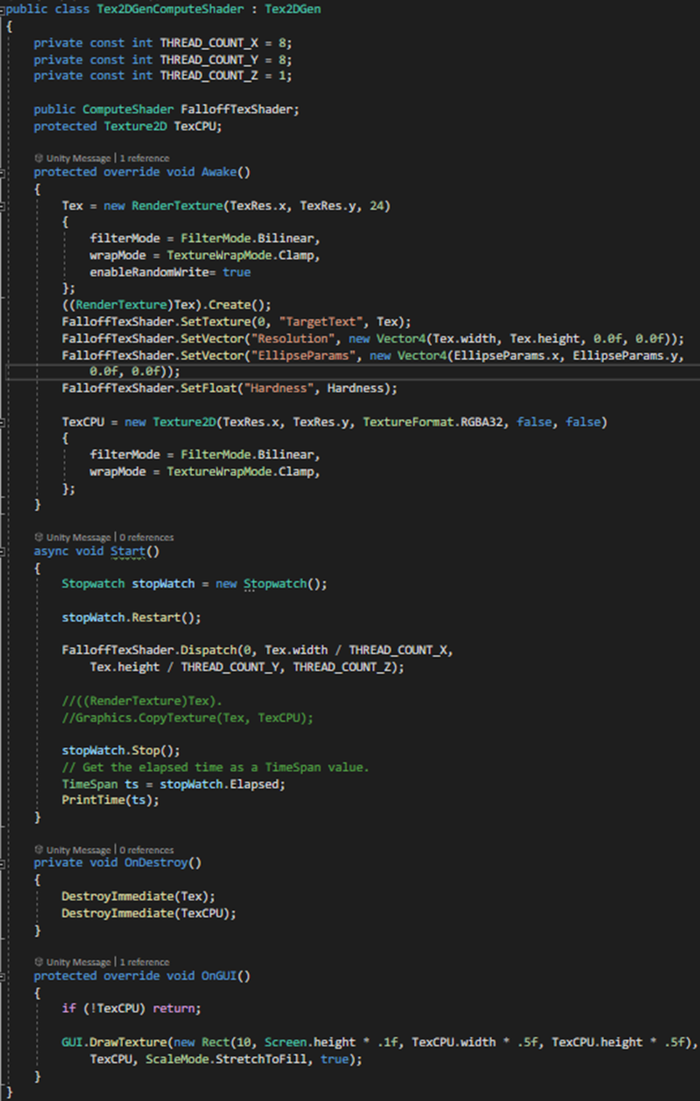
The following image shows the execution time of parallel execution using computer shading:
When we programmed for the parallel execution to take place through the GPU, for our case the execution speed tended to zero, because the CPU didn’t use its processing capacity to solve the texture pixels (for the purpose of the current article we don’t analyze the issue of GPU profiling, so we won’t go over the GPU’s execution time, nor core management by kernels, which is another subject matter). The process was as follows:
In the “Awake” phase, we sent instructions to reserve memory for the data structures we needed (vectors and textures).
It was necessary to send a RenderTexture to the computer shader, because these are the only ones that allow dynamic read-write.
In the “Start” phase, we sent the kernel execution with the number of cores that we were to use in the operation.
The execution time becomes “zero” because what is being sent is only one execution signal. Information is not being processed by the CPU; hence, our result tends to zero. This does not mean that the operation time is zero, but the processing time takes place in the GPU. All information processed by the GPU stays in the GPU. If we try to manipulate this data in the CPU, we have to bring it back. This process does take time and might impact execution time performance.
There are multiple ways to write code that executes through multithreading in Unity. Unity Jobs system is a powerful and optimized tool that helps developers achieve very good results in multithreading code. Programmers don’t have to worry about context synchronization, nor manually creating and destroying execution resources. One thing needs to be taken into account though: Unity Jobs’ imposed limitations on the use of structures and data value-type for information manipulation.
With C# Threadpool, we got erratic timeframes with a lack of uniformity. More research would be needed to determine if we can reach the same performance time as with Unity Jobs, most likely with a different information layout for pixel processing. We can also create our own low level threads system. However, it isn’t an easy task, and requires even more development time. C# Task is useful for introductions in parallel that require long-term execution, like when trying to analyze internet availability for a videogame.
Computer shaders look like an ideal course of action, because it “nullifies” our routine’s execution time, at least within the CPU. This can be debated, because computer shader data buffers were only set once. Probably, having a continuous binding towards the computer shader buffer could generate some delay in execution time (not likely to be considerable, but at least something we could measure). Another important factor that doesn’t have an impact in execution time with computer shader is the lack of calculated GPU’s information gathering. Such a process can be very costly from a computing point of view.
We hope that this article allowed to showcase how multi-threaded programming isn’t always magical in terms of performance; it can actually heavily impact a videogame’s overall performance if not implemented correctly. But, if implemented correctly, it is a great way to improve games’ performance.
Read more about:
BlogsYou May Also Like





