


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Nihilistic lead gameplay programmer Mark Cooke (Marvel Nemesis: Rise of the Imperfects) guides us through Nihilistic's approach to building a test system which, as he puts it, "lets a machine do the repetitive and time consuming tasks."

If you are working on a software project that is any larger than the most simple of applications, you need a build system and some form of automated testing. If you are working on a game project for a major console, you need build and test system to save your developers time. Let a machine do the repetitive and time consuming tasks, not your developers who have better things they could be doing.
This isn’t just about saving programmer time either - all disciplines can benefit from robust build and test systems. At Nihilistic Software, we have spent a comparatively small amount of time creating automated build and test software in relation to the large amount of time and stress saved from having these systems in place. Our build system is currently in use on its second commercial project. It was used to ship our last title, a tri-platform PS2 / Xbox / GameCube game, and is currently in production use in our upcoming unannounced PS3 / Xbox 360 title.
This article will outline the system we use, in the hopes it can be helpful to other developers in creating their own build and test frameworks, consequently improving the quality of their games by giving back more time for the important task at hand - making great games.
Nihilistic’s build system was developed in-house using a variety of both open source and commercial tools. It was designed to be flexible, easy to update, and distributed. The key components of the system are: a method for clients to request builds and have them fulfilled by servers, a scripting system to drive the build requests on the servers, a repository to store completed builds, and finally, a way to report results. Each component will be covered in turn, including how it was implemented.
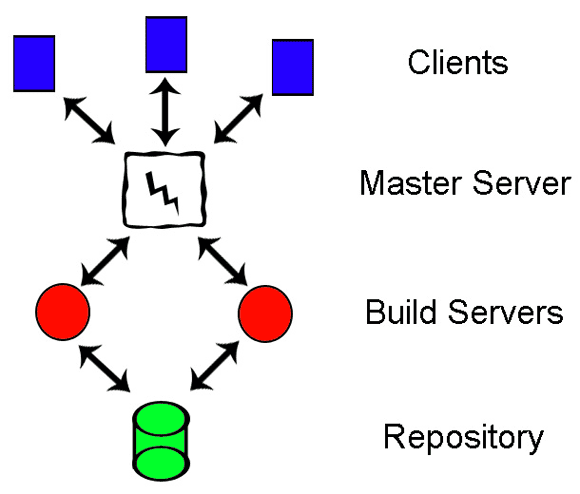 Layout of our distributed build system. Developers act as clients making requests to the master server that brokers said requests to build servers, storing results in a repository.
Layout of our distributed build system. Developers act as clients making requests to the master server that brokers said requests to build servers, storing results in a repository.
First, we needed a way to allow clients - the developers on the team - to request the build servers to do work daily. Although we do run many builds on a nightly basis automatically, it is often important throughout the day to deploy a new version of the game executable to the rest of the team - for example, when a programmer implements an urgent bug fix. Given that requirement, we needed a way to service requests at any time. The current solution in use is a paired .NET client and server application. Using the C# language and the .NET framework for tool development has proven quite efficient. If you haven’t already looked into the language and framework, it is easy to use, powerful, and has increased our tool production efficiency quite a bit. The build client application is a simple, data driven GUI that allows developers to pick from available build types and add them to the build queue. It also shows what is currently in the build queue, and allows users to cancel queued builds in case they made a mistake or wanted to cancel a less urgent build request to allow an important build to start.
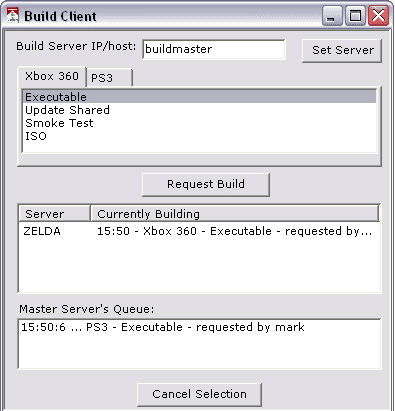
Example of the build client request application at work.
A build “mast er”server receives the incoming client requests. This application is in charge of brokering individual build requests and sending them to servers that can fulfill them. The master server knows each build server’s capabilities, because each build server registers itself with the master server and immediately tells it what types of builds it can fulfill. Again, this is totally data driven; new build types are simply added to an XML file, none of the client/server applications need to be recompiled. The master server is responsible for load balancing requests between servers. Distributing builds in this way allows us to have, for example, a build machine dedicated to compiling executables and another for bundling source assets into runtime engine data. The way that work is split between servers can easily be changed to whatever maximizes build system throughput in each individual project.
By having an independent build server which only contains the latest set of data, as opposed to developers doing builds on their local machine to be released to the team, we ensured that no stale or debug data or code entered the official build. Without a system that separates the machine making the official builds from the developers it is difficult to guarantee this.
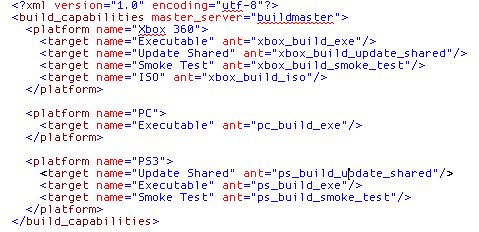
Build server capabilities are set per build server in an external XML file that defines what the specific server knows how to build. This is then communicated to the master server.
Once a build request percolates all the way down to a server that is actually going to do the work, we come to the second component of the build system - the scripting framework which executes the builds. We are currently using Apache Foundation’s open source ANT language. It is an XML-based scripting framework developed specifically for build systems. It excels at file system management and allows for conditional logic.
Additionally, it has the ability to create your own plugins if the built in functionality does not cover all of your requirements, though that hasn’t been necessary at Nihilistic. These scripts are responsible for doing the actual grunt work. They execute compilers (versioning executables on the way), run our own tools to parse and pack assets, create ISO images of game discs that are ready to burn, and launch our test system (more on that later). The scripting code is easy to maintain due to its straightforward method names and it’s even possible to data drive - ANT allows for external parameter files - so that the same script code can work with multiple projects.
That brings us to the third component of the build system, a place to store the results. For the majority of our build types, this means storing binary data in our source control management (SCM) application, Perforce. Since the team is already well versed in using Perforce on a daily basis for assets and code, it’s a logical place to have them easily retrieve the latest official builds. Unfortunately, it’s not always practical to store huge binary data in an SCM database primarily due to speed concerns. Large compiled asset bundles - which typically don’t benefit much from version history that an SCM provides - are stored on a networked server to be retrieved by clients via an automated batch file which is run on their local system. It’s important to note that although Perforce is a great application, it’s definitely not the only option - you should be able to employ any SCM application for this purpose. A popular open source option is the Concurrent Versions System (CVS).
 Snippet of an ANT XML build script, the syntax is largely straightforward.
Snippet of an ANT XML build script, the syntax is largely straightforward.
Finally, we needed a way to report the results of builds. Once a build has been requested, fulfilled, and checked into SCM or copied to a file depot, how is a client to know that occurred? For us, this was simple - if a build was successful, our build system sends an e-mail to the person who requested the build and a mailing list of perpetually interested parties (the build system maintainer, producers, key QA staff). If a build fails, for example because code could not compile, the build system sends an e-mail to the requester and a mailing list of the people who would likely know how to fix the problem along with an attached log that gives details on why a failure took place. In our example, the system sends an e-mail to all of the programmers with a compile log that directly identifies errors. In addition, the build server does not submit any data to the SCM application on failure to ensure no bad data pollutes the repository. For our medium sized team (for a next-generation console project) of approximately 50 people, this method of reporting has been straightforward and has worked well. On very large teams, especially ones with lots of people working remotely, it might make more sense to report results in a web page that the build system updates automatically.
Automated test systems for games have some intriguing problems that don’t apply to many other types of software. What does it mean for a game's overall behavior to be correct, especially when design can fluctuate frequently? How can you verify if a rendering system is outputting results that are correct? Is there even a definition of “correct” behavior when the typical rating systems for games are fun factor and whether or not something is subjectively visually pleasing? At a macro level, these questions are difficult to answer, however there are plenty of metrics you can measure fairly easily which can start to formulate an answer to some of these questions. What follows is an overview of the types of automated testing we have been successful with, specifically regression testing for crashes as well as benchmarking memory and performance in our game’s levels. This type of reporting is useful for all disciplines, but project managers take note - how nice would it be to receive a formatted spreadsheet of the state of which parts of the game are loading successfully and are operating within set budgets, automatically on all platforms, every morning? Read on to find out how.
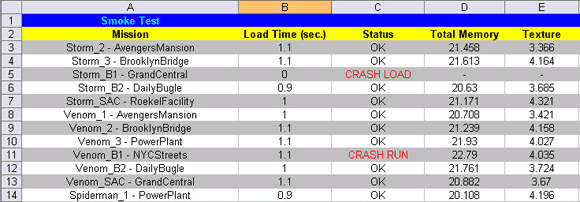
A portion of a memory test spreadsheet from a mid-development build of our last project.
Our automated test system was written in C# - it launches each level in the game in turn (parsed from the game’s own level list file, so it’s always up to date), executing the game directly into the level being tested on a designated target console, and then communicates over the network with the running game executable on the target console to retrieve report data. The majority of Nihilistic’s tools today communicate over TCP/IP to the running game to speed iteration time during content creation. The test system simply hooks into that as well - a highly recommended approach. If the game doesn’t respond to the test applications probing, it means that particular level crashed during load and that is noted and reported. Assuming it does respond, we know that it has at least been able to load and enter the main game update loop, where we begin to sample memory and performance data.
In non-retail executable builds, our game engine is constantly recording various memory and performance metrics. At the test system’s request, it can send that data back to the test tool across the network. All of this data is partitioned by the engine programmers into specific areas of interest. For example, memory data reports total heap, heap used, texture memory, model memory, physics memory, etc. Performance data recorded includes average FPS, number of objects being rendered, number of lights in effect at the time of probe, amount of time in milliseconds spent doing post-processing shader passes, and so on. Other useful metrics can also be recorded, such as load time, locations of spikes in performance, and memory leaks. We have budgets set up for the majority of these areas of interest that the testing tool knows about, so when an area is reported as over-budget by the game it is noted in the report.
In the end, all of this data is dumped by the testing application into a Microsoft Excel formatted XML file (see references for a simple C# library that helps facilitate this). Each game area or level of interest is a row, with columns for each of the different data types collected. This color coded spreadsheet marks in bright red anything that needs immediate attention such as a level that is currently crashing on load, or an area that is using too much texture memory. These tests run every night, though they can also be requested at any time, dropping off a spreadsheet with all this data in the e-mail box of nearly everyone on the project so that they know exactly what is going on with the game. This is especially useful in the later stages of a project when stability and meeting memory/performance constraints are of paramount importance.
Although the build and test systems we have developed at Nihilistic have worked well, there are areas where it could be expanded. The build request system should be web based, which would allow for slightly easier updating and would more easily give remote developers access to make requests. Another improvement currently under investigation is allowing the test system to automatically navigate the player through our ever growing levels to more accurately test the effects of gameplay variables. How this is done is very specific to the type of game being developed, so it will be left as an exercise for the reader. Finally, a recent addition to our engine that displays crash code callstacks on screen could be included into the test process as well, to report the full callstack for faster identification of problems when referencing the latest test report. There are many useful directions automated build and test systems can be taken in. The key is to evaluate the costs of developing a specific feature versus the amount of time it saves the team. In many ways it still makes sense to have a human do various forms of testing.
Developing a robust automated build and test system has saved everyone on our team countless hours. The framework was developed in house and took an insignificant amount of time in comparison to the savings. If you are working on a project of any kind of significant complexity, I would highly recommend implementing a similar system. Everyone on the team will thank you for it and the saved time can be devoted to improving the quality of your game.
References:
Perforce http://www.perforce.com/
CVS http://www.nongnu.org/cvs/
Apache Foundation’s ANT http://ant.apache.org/
Perforce ANT tasks http://ant.apache.org/manual/OptionalTasks/perforce.html
CarlosAg C# Excel XML Library http://www.carlosag.net/Tools/ExcelXmlWriter/Default.aspx
Read more about:
FeaturesYou May Also Like





