




Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
Game programmers write state-machines all the time, and yet the way we do it is often un-intuitive, over-engineered, or prone to mistakes. There is a better way, one that takes advantage of the new features of our game programming languages.


I have been working on games for many years now, most notably at Bethesda where I shipped Oblivion, Fallout and Skyrim. I am a programmer, and I have written things ranging from simple gameplay and AI logic to complex navigation systems, animation graphs and behavior trees!
One of the things that I have struggled with repeatedly over the years is always the same simple problem: managing the behavior of entities over time.
At its heart, the task is very straightforward: I need an entity to perform one or more actions over multiple frames, and to have some smarts about what it is doing in the process. This could be, for instance, a PowerUp that needs to flash every second until the player picks it up, or a Monster that has to react to the player entering a given radius. In short, most of your day-to-day game logic or simple AI.

Game programmers write this kind of code so frequently that we don’t really give the task a second thought. We even have a well established way of approaching the problem: a State Machine.
And the problem isn't with states machines themselves - they are the right tool for the job - the problem is with how we actually write them.
Having implemented many variations of the state machine model in my own systems, and looked at several more in the wild, it has become apparent to me that our implementations are fundamentally flawed. They are always either prone to mistakes, un-intuitive or over-engineered, especially as the system grows in complexity.
This is not something that seems to happen nearly as much with library, low-level or math-heavy code. Best practices and design patterns are well known and do work!
But dealing with persistence of state data across frames messes everything up. All of a sudden, a variable that was locally scoped needs to become a class member. What looked like a simple if-then-else block has to turn into a confusing lookup table. And before you know it, you are declaring state objects, defining transitions and implementing a whole state machine framework for something that, conceptually, should only require a few lines of code.
The reason why we run into this trouble, the fundamental flaw I just mentioned, comes from the limitations of our game programming languages (C++,C#, etc.). They are not very good at interrupting a logic flow, doing something else (like rendering) and then resuming that logic flow later. They are so bad at it, in fact, that for big heavy computations, we have been using OS-level workarounds to the problem for several decades: namely Threads (and Fibers).
But threads are a really heavy duty tool. On Windows systems for instance, each thread requires at least 1 Meg of physical memory and has a significant performance impact on startup and exit. No one would ever consider giving every unit in an RTS their own thread!
And so instead we jump through hoops to store state data across frames and fake this uninterrupted logic flow we wish we had. We end up writing code similar to this:
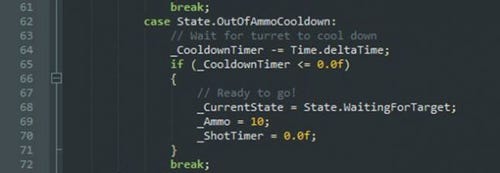
But there is hope, over the last decade, our game programming languages have gotten some pretty amazing new features. Things like Coroutines, Continuations and Closures to name a few. I am going to show you how to take advantage of those features, and a few more, to write game code that is much simpler, intuitive and a lot less prone to mistakes than what you may be used to.
Let's start with an example then. Below are two versions of the same entity: a Turret that tracks a target, fires one round every second ten times, and then waits for 5 seconds to cool down before looking for another target. The first version (left) uses a common technique - switching on state variables - and the second (right) takes advantage of these new language features.
Note that the code is written in C#, but it could be written in C++ with very little change.
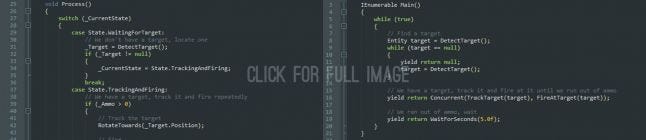
Now if you use Unity, you will be familiar with those yield statements, and indeed, the code is based on the same language feature as Unity’s coroutines. It is the ability to write methods that return a value, suspend execution, resume from that very point in the code when they get called again, return another value, etc... They are coroutines, but are also sometimes called generators, or specifically in C#: iterators.
How do they work? By leveraging the compiler! I will spend some time covering the internals of these coroutines in the future, but for now I'll mostly focus on the effects of using them.
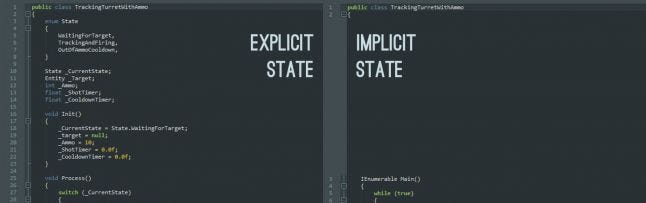
Looking at the sample code again, you can see that the coroutine version of the Turret doesn’t have any member variable. That's because when using coroutines, all the state data is stored as local variables in the methods that need it, or gets passed down as parameters.
As I mentioned, the compiler does a lot of work under the hood, and here it ends up generating the persistent state data for us. It does so in a way that is both transparent and semantically correct. This is great, because even though in reality some of the data is stored in memory somewhere that isn’t the local stack, those variables behave completely like local variables.
In other words, the state data is implicitly generated for us! In fact the entire state machine is implicitly generated.
Another significant advantage of this implicit generation is that our state data is now locally scoped, and therefore protected from accidental misuse.
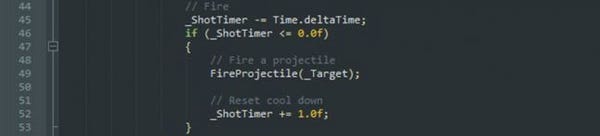
In the standard version of the Turret for instance, the _ShotTimer variable is a private class variable. So while it can not be modified from outside the class, it is very unclear what internal methods actually use it. More importantly, it is unclear which new method should modify it to maintain functionality!
In the coroutine version however, the delay between shots is stored locally to the FireAtTarget() coroutine. Nothing else can mess with that timer, because nothing else knows about it!
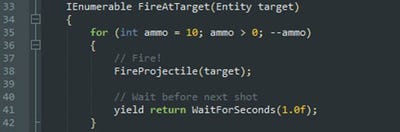
With coroutines, variables can be restricted to the lowest scope possible and then promoted to broader scopes as needed by declaring them sooner or passing them as parameters. This is very useful to protect yourself from accidents. As a general rule, you want to be allowed to expose your data, not have to remember to hide it!
Keeping everything within local scope also has the benefit of making the code more readable. Let’s say I wanted to start a particle effect when the Turret starts searching for a target, and kill it when it finds one. This is how I would do it:
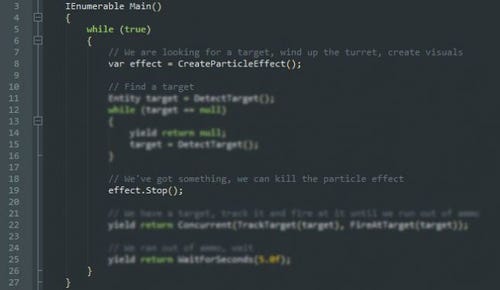
Where I declare and use the particle effect variable provides most of the information I need to understand what it is for. It is the exact same reason that most programmers don't like having to declare variables all at once like we had to do in C89, and it’s also the same idea behind RAII in C++.
The next strange thing that you might notice is the following line:
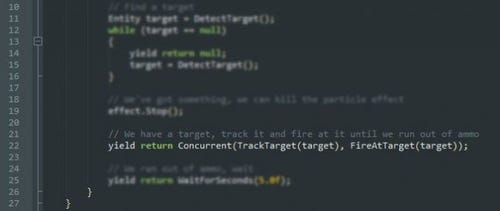
What is happening here is this:
TrackTarget() and FireAtTarget() are both coroutines themselves, not simple methods.
Concurrent() is a utility method that builds a special object that the coroutine framework understands to mean:
Execute the two coroutines passed in as arguments, in parallel (time-slicing)
Stop as soon as one indicates a failure
When that happens, return execution to the current coroutine
This is in contrast to the majority of the yield return null; statements in the example code which are understood by the framework to mean: 'resume the current coroutine on the next frame'.
As you can imagine, the concurrent block quickly becomes very powerful. Having the ability to spawn and synchronize coroutines in parallel changes how you approach problems. In fact it is a lot more analogous to how we think about complex behaviors.
I will cover the full implementation of the concurrent block in the next article, along with the rest of the framework. I'll also introduce other logic-over-time concepts such as behavior trees. You'll see, coroutines, continuations and closures make a powerful combo!
For now though, I will leave you with these two great talks on coroutines in C++14/17.
Read more about:
Featured BlogsYou May Also Like





