


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
Zynga's Python-focused analytics platform

Zynga analytics is a team of over 70 analysts, data scientists, and engineers distributed across 6 counties supporting development and live operations for dozens of mobile games. While our studios leverage a variety of technologies for storing and processing tracking events from our games, we have standardized on Python as the common language to use for analytics and data science tasks, such as building reports, running A/B tests, and deploying machine learning models. This alignment on Python for our analytics stack has increased the productivity of our analytics organization and has enabled Zynga to more rapidly explore new technologies. We’ve built upon the analytics capabilities that Zynga is known for, such as A/B testing and game tuning, and are now using Python to deploy services with cutting-edge technologies, such as reinforcement learning for personalizing games.
One of the biggest motivators in moving to Python for our analytics stack was to have a standard language across our analytics, data science, and engineering teams. This moves our analysts and data scientists closer to the ecosystems that our engineering teams use to deploy systems. We also had the following motivations for building our analytics stack with Python:
Open Source: We’ve been able to replace some of our proprietary tools with Python replacements. For example, we’ve migrated our ETL tooling from Pentaho Kettle to Apache Airflow.
Machine Learning (ML): Most cutting-edge work in machine learning is being developed in Python, and using this language for our analytics stack ensures that Zynga can apply deep learning advances.
Notebook Environments: We use the JupyterHub notebook environment as an approachable interface to Python for our analytics and data science teams. For distributing computing, we use the Databricks notebook environment to enable our teams to leverage the Spark platform.
Robust Ecosystem: In addition to notebook environments, Python APIs are available for many big data tools, including serverless functions, stream processing, and data stores. Python can be used to build command line scripts, web applications, and complex data pipelines.
We began our migration to Python starting in 2018, and now use Python for the majority of our analytics workflows. Before Python, our analysts’ workflows consisted primarily of SQL and in-house tools for reporting, and some data scientists used R for machine learning. In addition to Python, our analytics stack is built with Java and Go for services with high throughput and low-latency requirements.
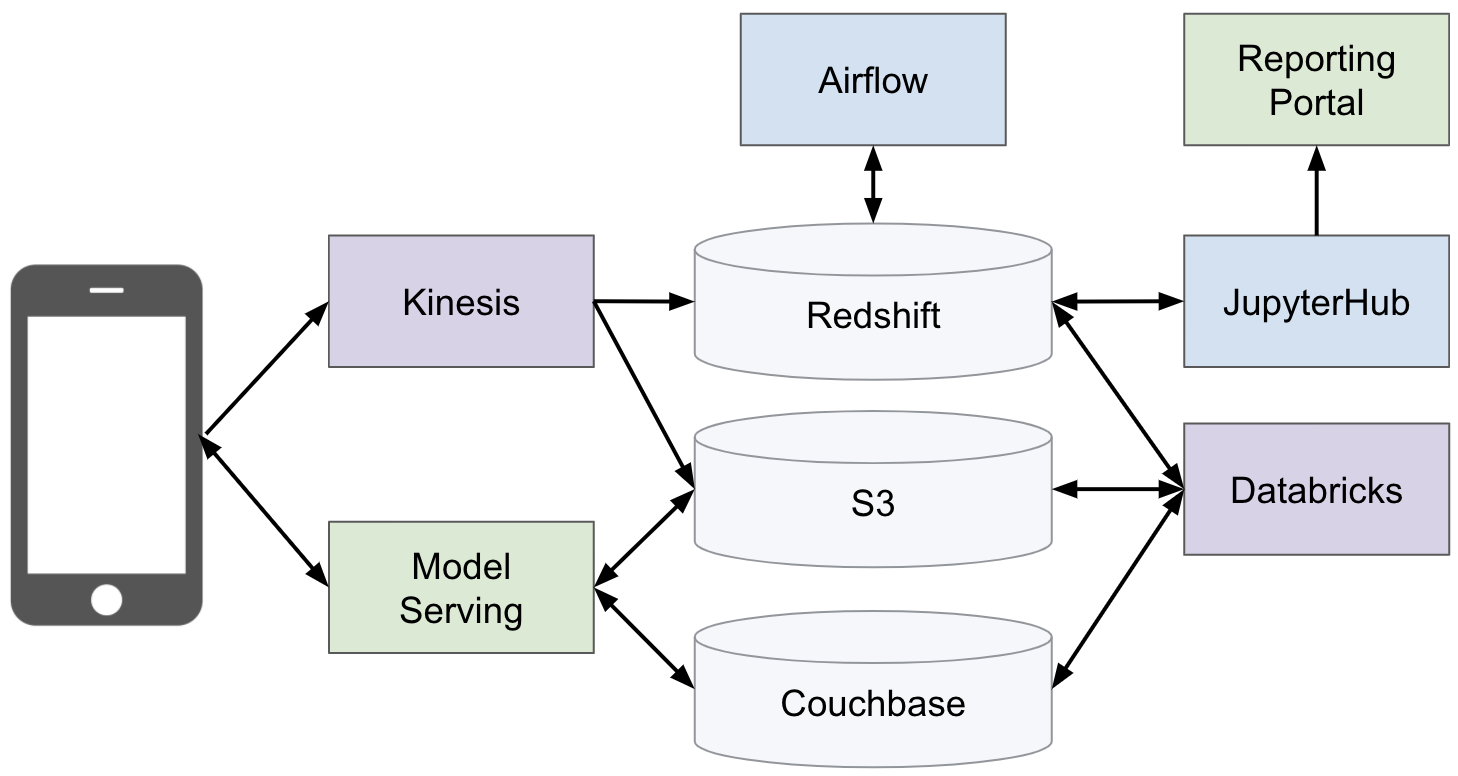
A simplified view of the Zynga analytics stack.
The Zynga analytics platform is built on AWS, and uses a combination of open source, in-house and vendor services. A simplified view of the components in the platform are shown in the figure above. The platform uses Redshift as a data warehouse, S3 as a data lake, and Couchbase as an application database. It also includes the following services:
Amazon Kinesis: A managed data streaming service that we use to send data from mobile devices to AWS, where Kinesis consumers batch events and save the results to Redshift and S3.
Apache Airflow: Zynga uses Airflow to schedule ETLs for data modeling and to aggregate events into summary tables. We also use the Databricks operator to schedule batch ML models.
JupyterHub: We use Kubernetes to host JupyterHub notebooks and provide a personal workspace for analysts and data scientists. Teams can share notebooks using GitHub and publish notebooks to the reporting portal for consumption by game teams.
Databricks: A notebook environment for PySpark, which enables our analysts and data scientists to author workflows that can run on a cluster of machines.
Reporting Portal: An in-house tool for centralizing all of our reporting into a single location, including Jupyter notebooks, Tableau reports, and custom web applications.
Model Serving: An in-house tool that supports serving precomputed model outputs in Couchbase and real-time model application using Amazon SageMaker. While the web server interface of this component is written in Go, it uses Python for model application.
In addition to these components, the analytics stack includes a few custom web applications that are written in Java and Python, hosted using Docker and Kubernetes, and surfaced to Zynga teams in the reporting portal.
Visualizing gameplay data with JupyterHub
Jupyter notebooks are one of the core tools used by our analytics team, and we’ve integrated notebooks into our reporting workflow. JupyterHub is a multi-user version of Jupyter, which is an interactive Python environment for exploring data sets, creating visualizations, and building predictive models. Our goal in moving to Jupyter notebooks was to provide a standardized environment for analysis, where teams can share notebooks and reuse scripts across different games. The result of this migration is that analysts spend less time writing SQL queries, and instead build parameterized reports that our product managers can use to track KPIs and evaluate the performance of newly launched features.
One of the ways that we’ve improved the productivity of our analysts is by moving from proprietary, in-house tools for reporting to open source solutions that are integrated into our reporting portal. Jupyter notebooks are now a core component in our reporting portal and analysts can publish parameterized notebooks to this system. The result is that anyone at Zynga can run reports to better understand how product updates and new features are impacting our games. To achieve this functionality, we had to align on a fixed set of libraries for the reporting environment, but the result is a system that enables analysts to provide self-service analytics.
The Jupyter environment is typically used for exploratory data analysis, while model production is handed in our Databricks environment. We’ve built an in-house Python library for connecting to our data warehouse, which enables notebooks to retrieve and save data sets. Our core set of libraries also includes visualization libraries such as Bokeh and common data science libraries such as numpy, pandas, scikit-learn, and statsmodels. These packages enable our analytics teams to measure the performance of first-time user experiences, build forecasts of game performance, create segmented audiences, and explore the potential of machine learning models for deployment. The end result is that analysts spend less time working directly in a SQL IDE and instead build workflows that can be shared across teams.
Successful DAG runs on Airflow.
Apache Airflow is an open source tool for scheduling workflows that was initially developed at Airbnb. It is written in Python and workflows are authored as Python scripts called Airflow DAGs. A DAG defines a set of tasks to run and defines the ordering of tasks, where a task can specify a query to run, a Databricks notebook to run, or a variety of other actions. While we initially migrated to Airflow as a replacement for Pentaho Kettle to schedule our database ETLs, we now use the tool as our primary scheduling tool for analytics workflows.
One of the key benefits of moving from a proprietary to open source solution for scheduling database queries is that we’ve been able to open up the tool to more of our teams, and authoring Airflow DAGs is now part of the job function for our analysts and data scientists. Analysts are now able to apply their domain knowledge about our games to create useful summary tables that can be used for more efficient analyses and quicker report generation. The result has been that the teams with more knowledge about the types of events that are being tracked in our games are now hands-on with the data modeling process in our data warehouse.
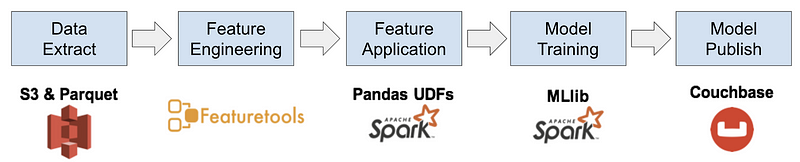
Building Propensity models with Apache Spark.
Apache Spark is an open-source framework for authoring distributed workloads using familiar languages, such as PySpark, which is the Python interface to Spark. PySpark enables our analysts and data scientists to author scalable model pipelines that run on clusters of machines, where the intricacies of distributing and parallelizing workloads are handled by the platform. Zynga has been using the Databricks platform as our Spark ecosystem since 2017, and the platform provides a collaborative notebook environment that has accelerated our ability to deploy ML models.
Our analytics teams leverage a variety of different Spark features and Python libraries to build model pipelines and perform large-scale analysis with PySpark. While our initial approach to building ML models on Spark was to use the MLlib framework for distributed model training and application, we’ve been exploring other approaches for building more accurate models. For example, we have achieved good results using the hyperopt library to perform distributed hyperparameter optimization of XGBoost models. We also leverage the Pandas UDFs feature in Spark to distribute actions such as automated feature engineering with the featuretools library. In addition to building classification and regression models, our data science team has authored notebooks for performing economy simulation, archetype analysis, and anomaly detection.
We have authored an in-house library for PySpark, which makes it trivial to read and write to the different data stores within our analytics platform. Our data scientists are now using this library to author end-to-end model pipelines, which has significantly reduced the amount of time it takes for our teams to iterate from a prototype model to a model in production.
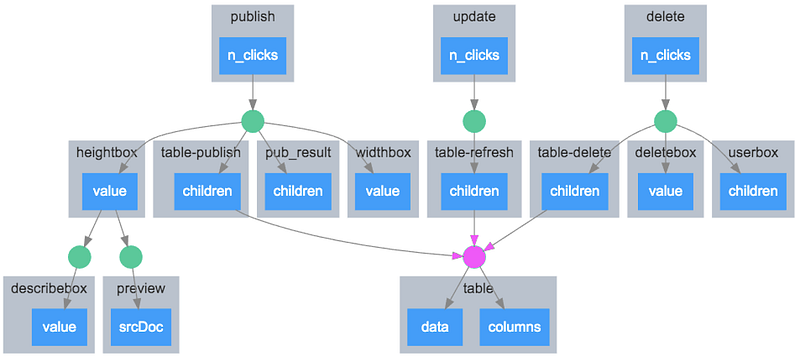
A callback graph for a Dash web application.
The Python ecosystem includes a variety of libraries for authoring web applications including flask, gunicorn, dash, and streamlit. Web application development is a new area of interest for our data science and analytics teams, where the goal is to build tools that can be used internally by our game and publishing teams. For example, our marketing analytics team is building web applications that are used by our user acquisition team for managing campaign budgets.
Dash and streamlit are Python libraries that enable Python coders to author interactive web applications without writing a single line of HTML or javascript code. Instead, Python code is used to define the layout of the web application and set up callbacks, which are Python functions that update the application in response to user input. This approach makes it much easier for our teams to write utility web applications, such as endpoints that marketing can use to generate CSV files of custom Facebook audiences. Using these libraries means that our analytics teams can now author web applications that would have previously required substantial engineering support. We deploy these applications using Docker and Kubernetes, and surface the web applications through our reporting portal.
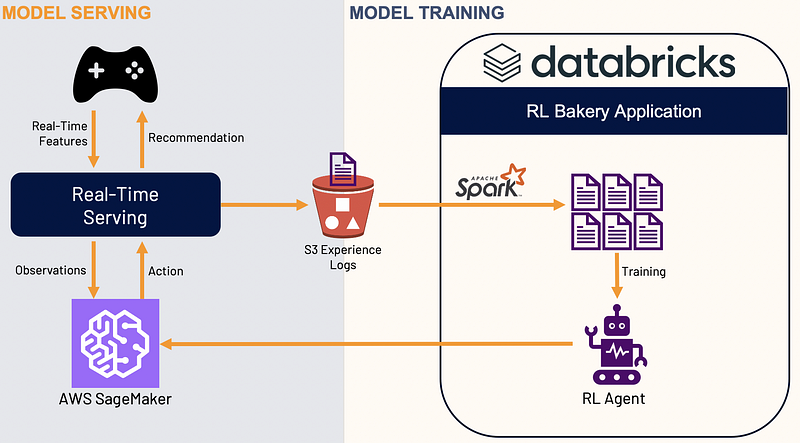
Model training with RL Bakery and serving with AWS SageMaker.
The model serving component in the Zynga analytics stack supports batch and real-time model predictions. For batch model predictions, we schedule Databricks jobs using Airflow, where the model predictions are computed daily and then saved to Couchbase. For real-time predictions, the game client passes session state to ML models deployed oN AWS SageMaker.
The model serving component also supports reinforcement learning models, where a reward function is used to train the model online in real-time. For example, a model can determine the best time to send a notification based on the player’s gameplay patterns. This is an area where Zynga has contributed back to the Python open source community, with the release of RL Bakery.
Zynga began migrating to Python for our analytics stack in 2018, and now the majority of analytics workloads are authored in Python. Standardizing on a single language has enabled our analytics organization to share workflows and increase the productivity of our analysts and data scientists. We’ve also been able to significantly decrease the amount of time it takes for data scientists to put models into production, and provide cutting-edge solutions for personalizing our games.
You May Also Like





