




Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
Writing an Engine from scratch can be a daunting task. With a broad understanding of Memory Management, we delve deeper into the fine details.

Part 1 - Messaging
Part 2 - Memory
Part 3 - Data & Cache
Part 4 - Graphics Libraries
In Part 1 we started of our Engine development cycle by first designing an Architecture that would suit our Game. We then realized that a Game Engine, like any software, is nothing more than a big data crunching machine. We have some data (Game Assets), the user can modify some data (Input), we process that data (Game Logic) and display the resulting data (Rendering). Thus, from a developer viewpoint, managing that data is the most important aspect of the Engine. For now, we'll ignore the fact that gameplay seems to be an important aspect to the Player. But, what does he know.
In order to work with data, we chose a Top-down approach, going from overall Engine Architecture right down into Memory Management. But we still haven't talked about the actual data we will manage. We will do this here.
We will also look at some important Cache related performance issues when we work with data in order to make educated design decisions on how to structure it.
Be warned, as we are going to work at a lower level than before, there might be Code involved.
Data
Let's say our Game will need a Deck of 60 Cards. How do we represent that in code? A Stack? What if we need to shuffle it? What if a Card is randomly placed inside the Deck, is a Stack still appropriate?
Those are alot of design questions we face while coding. It all boils down to this: What we are really interested in is something very fundamental about data. Something that applies to all shapes and sizes we might encounter in the wild - How we organize it. Or, as these organizational elements are also called, Containers.
At first glance, this might seem like something we covered in Memory Management. But it is not. The difference is subtle, our Allocators in Memory Management tell us where we store the data and our Containers tell us how we store our data.
So what is a Container? Well, you probably know alot of them, but might not have used this term before. Just to name a few:
Arrays
Linked Lists
Trees
...
and on.. and on..
Basically a Container is just some way of organizing pieces of Information. These small pieces might be simple variables, structs or even classes - or in our case, Game Cards.
The goal of this Article is not to teach you about the types of Containers themselves. The goal of this Article is to bridge our knowledge of Containers to our Allocators and find good and Cache-friendly ways of designing these for use in our Engine. And to be honest, this will be no easy task. I'd even go as far as saying, this is probably one of the hardest parts of writing an Engine.
But first, let's start with something simple and take a look at Containers from our Memory Management background before we move on.
The Linked List
As you probably know, a linked List is just a collection of elements, each containing some piece of data and a pointer to the next (and/or to the previous) element in the List. It's an okay solution to our Card Game, probably better than a pure Stack implementation, if we need random access or shuffling.
The obviously cool thing about linked Lists is, that you can store each element wherever you want in Memory and that this decision won't affect the relative position of the Element inside the List. Perhaps you have even implemented a linked List in the past this way, storing Elements somewhere in Memory and linking them up later on.
In short, a simple, yet very bad implementation of a singly linked List in our imaginary language might look like this:
struct listElement
{
someObject data;
listElementPointer nextElement;
};
class SinglyLinkedList
{
public:
void addElement( someObject item )
{
if ( firstElement == null )
{
firstElement = new listElement();
firstElement->data = item;
lastElement = firstElement;
}
else
{
lastElement->nextElement = new listElement();
lastElement->nextElement->data = item;
lastElement = lastElement->nextElement;
}
}
void deleteElementAt( int index )
{
listElementPointer currentElement = firstElement;
listElementPointer previousElement = firstElement;
for (int i = 0; i < index; i++)
{
previousElement = currentElement;
currentElement = currentElement->nextElement;
}
previousElement->nextElement = null;
delete currentElement;
lastElement = previousElement;
}
// Iteration functions.... etc...
private:
listElementPointer firstElement = null;
listElementPointer lastElement = null;
}
(Ignore all the potential for errors in the above code and focus on the use of new and delete)
Imagine we ran that code in our Engine. By adding single elements to our List, using the standard allocator that is given to us by our Language, we will seriously spread out the area where this simple List stores it's elements. They could be anywhere.

Smells like Memory Fragmentation. How can we fix this? Well, we already know how from Part 2! By allowing our SinglyLinkedList to use one of our Allocators or Allocation Techniques. Let's go with a Pool-based Allocator. By replacing new and delete inside the List Class with our allocate function, we constrain our Linked List to live entirely on a pre-defined area in our Memory.
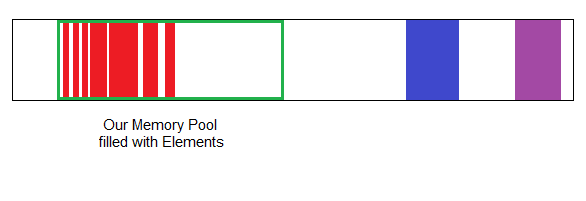
Pretty neat, right? Sure, we have to be certain our Pool is large enough to fit all cases our List might encounter, but more often than not, we can actually estimate this maximum size. For example, our Card deck might never grow beyond 200 Cards.
This isn't just some special Game development thing to use custom Allocators on Data Containers. As a matter of fact every Container in the Standard Library in C++ allows you to use a custom Allocator. So the above List would simply look like this in C++ using our own little myAllocator.
std::list someList;
Pretty neat, if you followed the C++ guidelines on writing Allocators. I won't recommend, nor not recommend using the Standard Library, but if you are coming from a C++ Background, it is definitely worth reading this first!
Okay, enough C++ specific things you probably don't care about, we just wanted to look at a simple example!
What's the big deal, I know how to write Containers and we already covered Memory Management!
Well, apart from avoiding all the pitfalls we discussed in the last Article, there are a lot of speed related issues we face when designing Containers. The two big ones we will face are:
Container Overhead
Caching
We will mainly talk about Caching, as this is can become very important and currently is a very "in" thing to do. Furthermore, the issue of Overhead we face is actually tightly coupled to this subject anyways.
At this point you will probably recall this Quote by Donald Knuth:
"Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%."
This is indeed true most of the time. But what we are going to do and talk about is none the less necessary at this stage. Why? For one, we already know it's going to be slow if we mess up, thus we should design it efficiently from the beginning using some of the methods we are going to talk / have talked about. Furthermore, we are designing something as fundamental as our data structures at this point. Optimizing this at a later stage will be a huge can of bugs we don't want to open, so why not take the time now and design it well once.
Caching...
Before we start to talk about Cache:
if you are actually writing an Engine that needs some hardcore Data/Memory handling right now, concider reading this Article by Ulrich Drepper instead of my babbling. It's worth it.
if you are writing a simple Engine or are just interested in Engines, you could continue reading here. But bookmarking the above Article never hurts.
So, what is a Cache? As the name suggests, it is some form of Storage. When talking about Programming, it mostly refers to a Region of Memory that temporarily stores hard-to-get data to avoid fetching it again. This alone is a very interesting concept, as we saw how slow RAM access can be.
And indeed, this is exactly how our CPU operates. Pretty much every piece of Memory coming from the RAM is stored in the Cache, just in case we might need it again later. Schematically it looks something like this:
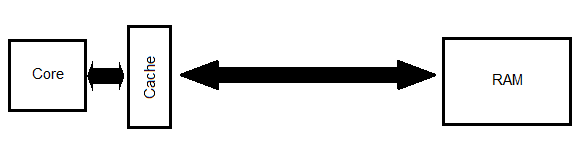
I deliberately drew the RAM far away, as to symbolize the slow access time. It's okay to think of the Cache to be the middle man between the CPU and the RAM. Let's just stick with this picture for now and assume, that everything that is coming from the RAM is actually first stored inside the Cache, before the CPU gets it.
So why not just use the Cache the whole time instead of the RAM?
Space
Let's look at an actual Processor and its Cache.

(That's an Intel Core i7-4960X, Image by Intel, found through Google)
The above Processor "only" has 15 MB of Cache and look at how much space that takes. How can we increase that? We could slap another 15 MB of Cache on each side of the Cores and double the Cache (in theory), but then, we start running out of space. So, what needs to be done? We need to go farther away. At the next distance interval, we might be able to add another 60 MB. We will thus need to go farther and farther away from the actual Core on the Die in order to achieve the large amounts of Memory we have in our RAM.
We'd end up with a huge Processor Die. And this is followed up by a lot of Problems. Apart from heating issues, the distance between the outer edges of the Cache and the Cores will be problematic. This distance will increase the time it takes for the Memory to travel back and forth. Something we tried to avoid. Not good.
Speed
What? Yes, having too much Cache could hurt the speed our Memory runs at. We would gain alot more overhead just to address our Cache (We will see why later). This might seem negligible at first glance, if we concider that we wouldn't be using our RAM anymore / as often. But our main Goal here is to reduce RAM access anyways, thus introducing more Cache by sacrificing Cache speed would be counterproductive.
Cost
Well, Cache isn't just faster than your usual RAM just because it's closer, it's also faster, because of the way it is manufactured. Cache mostly uses SRAM (Static RAM - basically, just a few Transistors forming a FlipFlop) to store it's information, instead of the typical DRAM (Dynamic RAM - formed using a capacitor to hold the bit and a transistor) found on the RAM sticks inside your PC. Sadly, having large arrays of SRAM is alot more expensive than using large DRAM arrays, hence cost becomes a Factor.
L1, L2 and L3
In the Pictures we looked at, we had different types of Cache called L1, L2 and L3. So what do they mean? In short, they just express how close the Cache is to the actual Core, indicated by the use of L as in Level.
So an L1-Cache would be the closest. Being the closest also means, that it is the smallest of the Caches, due to size constraints. Usually the L1 is local to a single Core, i.e. only that one Core has access to it. The size hasn't changed much in the past few years and it's pretty safe to assume that we have about 32KB - 64KB of L1-Cache per Core.
L1 (hit) Access Time: 0.5 ns - 2 ns
The L2-Cache is a bit larger than the L1. Starting with the L2, Cache's might be shared between Cores, so 2 Cores sitting next to each other might have a local L1 cache each, but share their L2 Cache. Here sizes start to vary more. It's roughly 4 - 8 times the size of the L1-Cache.
L2 (hit) Access Time: 4 ns - 7 ns
The L3-Cache (if present) is pretty much just the largest Cache and often shared by multiple Cores. Its size varies the most, but if you had to guess, you could assume that it's around 1/1000th the size of the RAM in use. (For example, an 8GB mid-range PC would probably run a mid-range Processor with 8 MB of L3 Cache)
L3 (hit) Access Time: 15 ns - 50 ns (depending on how it is shared)
Notice how the Access Times jump, even though all these Caches are on the same Die? Confirming our suspicion that more Cache wouldn't necessarily be faster.
Why do we have 3 Levels?
For this, let's take a detailed look at a previous graphic.
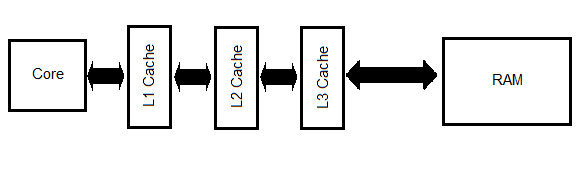
A simple way of looking at how it works is,
Core needs a certain Memory Location (for example to multiply it by some number)
Check if the Memory Location happens to be in L1.
No? Check if the Memory Location happens to be in L2.
No? Check if the Memory Location happens to be in L3.
No? Fetch it from the RAM.
The last "No?" - not finding the Memory in the Cache and having to get it from the RAM - is mostly referred to as a Cache-miss.
So what happens on a Cache-miss or when fetching Memory from the RAM in general?
A request to the RAM is made for the Memory Location in question. The RAM sends that piece of Memory to our Cache and we store it. Sounds pretty neat. But say we don't have any space left? We must therefore kick out some part of the L1 Cache, or our Core has no way of accessing it! Ouch...
Usually, the piece of Memory that is kicked out of the L1 Cache is the one that hasn't been accessed the longest time ago. But still, we lose it, and if we were to need it again, we would have to go back all the way to the RAM and get it.
Or do we? Like we saw earlier, the L2 Cache is bigger than the L1 Cache. So, instead of completely kicking out the oldest Memory out of the L1, we simply kick it to L2 and store it there.
But what if L2 is full as well? Well, to make space we then kick the oldest L2 Cache piece of Information to L3 and can safely store our data coming from L1.
What happens to the oldest Memory on L3 if we run out of space there? That's gone! If we ever need it again, we need to fetch it from our RAM.
Speedwise, avoiding as many Cache-misses as possible is our primary goal when designing data structures. But to understand Cache-misses better, we need to learn how data is actually represented in the Cache, how it gets send there and how it gets send back!
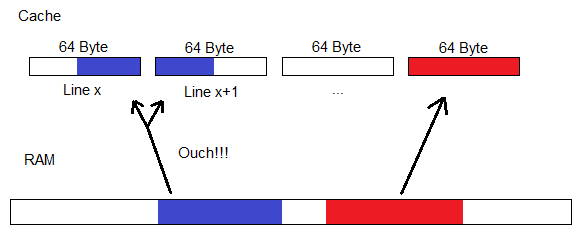
Cache Line
We learned that Memory from the RAM is first passed to the Cache before being processed in one of the Cores. The currently executed Program does not know this, therefore, the Program will want to fetch some Memory Location as it is mapped on the RAM. This means, our Cache must be smart enough to realize that if the CPU wants Memory Location 0x0033FA22 on the RAM, this would reference Position 7 in the Cache.
Therefore, there must be some sort of look-up table that maps certain RAM Locations to their spot on the Cache. And this look-up table has to be stored somewhere near the Cache.
Obviously, it would be pretty stupid to have a seperate Cache location for each Byte or Word we load from the RAM. Our look-up table would be bigger than the Cache itself!
Therefore, we don't just map single Bytes of RAM to the Cache, instead we map little 64 Byte chunks. And we call these little chunks a Cache-Line.
(Note: 64 Byte is about the average Cache-Line size you might expect around the date this Article is written.I will keep using 64 Byte Cache-Lines for the remainder of this Article. Replace by X if this should not hold true for your Processor / Alternate Timeline)
Storing entire Cache-Lines reduces the overhead of mapping Cache Locations to RAM Locations. Furthermore, if we were to restrict the mapping to only map to addresses that are a multiple of 64 Bytes, we can actually shorten the Reference Address we store for the RAM location, by omitting the last few bits entirely, as they are always 0.
And indeed, we find that Cache-Lines are loaded at 64-Byte offsets or boundaries from the RAM.
We therefore load entire 64 Byte chunks from the RAM into the Cache "at once". Well, not entirely "at once", as the Bus between the RAM and Cache isn't wide enough to achieve this. It would require 512 bits of Data to actually get the entire Cache-Line at once. That just doesn't happen with current hardware. Most CPU's
wouldn't even have enough pins dedicated to Memory to actually achieve all that. Which is fine, the entire Cache-Line gets read piece by piece.
The 64 Bytes we load are the 64 Bytes that contain our requested Memory Location.
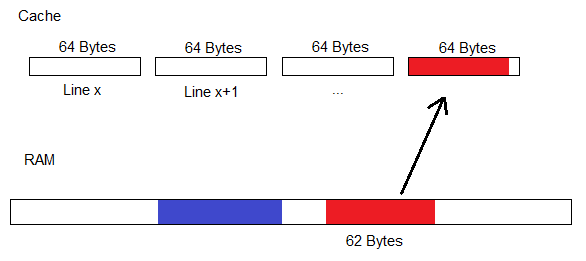
Now, we don't need to kick individual Bytes around from Cache to Cache if we need space, we can kick entire Cache-Lines between L1 and L3.
Writing
We've talked about reading Data from the RAM thusfar. But what about writing Data to the RAM? Well, it should be obvious that we can't just write Data to the RAM without editing the Cache Line as well. Otherwise we would be working with outdated Data Sets most of the time.
What actually happens is, that the Memory gets altered in the Cache and is only "occasionally" updated / written to the RAM. For Single Core Processors this process works pretty well. We only work with Memory that is on the Cache. So, we only need to modify the Cache and not the RAM. Only once that specific Cache-Line gets kicked out do we need to write to the RAM as a means of saving the data.
So, using the same variable that resides inside the Cache over and over will be very efficient, as it won't get pushed to the RAM until it's kicked out of the Cache.
For modern Hardware, this no longer applies. In current Computer Architectures we will face multiple Cores that might need certain Memory Locations. Furthermore, we might even face other Hardware Components (Example: Graphics Chips on the Motherboard) that have access to the RAM. Thus, our "occasionally" writing back to the RAM won't cut it. We need some more sophisticated protocols. And we will take a closer look at this scenario in a bit.
For now, we are ready to set up a few guidelines.
Our first Lesson
So, we request a few Bytes of RAM and the entire 64-Byte Line it resides on gets loaded into the Cache:
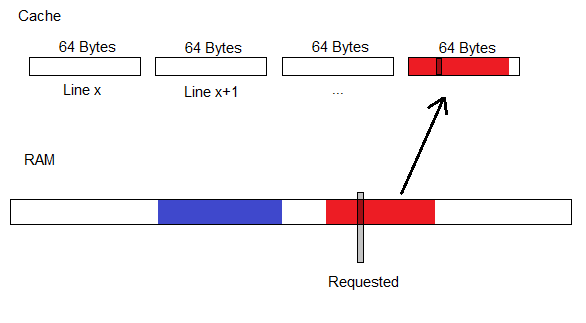
Wouldn't it be wise to store any data we might need in the near future in that same Cache-Line, thus avoiding a future RAM request later on?
Bingo!
It's such a simple concept. We just try to pack our Data into the same Cache-Line if we know we will need it soon. And this is our first lesson we take away from this.
Let's take a look at probably the most used example to demonstrate this point.
Spot the difference in these two Code samples and try to figure out, why one might be slower than the other.
Code 1:
for (int i = 0; i < 5000; i++)
{
for (int j = 0; j < 5000; j++)
{
arrayA[i][j] = arrayB[i][j] * arrayC[i][j];
}
}
Code 2:
for (int j = 0; j < 5000; j++)
{
for (int i = 0; i < 5000; i++)
{
arrayA[i][j] = arrayB[i][j] * arrayC[i][j];
}
}
Notice anything?
Yes, all that has changed is the order of our for loops. Doesn't seem to wild? Imagine how those Arrays are represented in Memory.
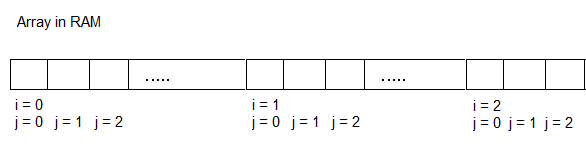
Now, let's take a look at how Code 1 accesses that memory one-by-one:
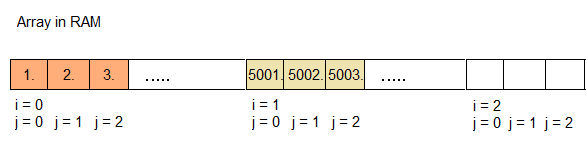
Ok, good. And now let's take a look at Code 2:
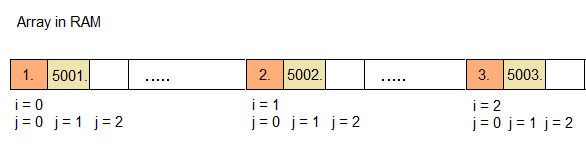
Huh... Wait a minute... Are we jumping 5000 Elements each time? Wouldn't that imply that we have to load a completely new Cache Line for each iteration of the loop in Code 2?
Yes we would. And yes, this is slow.
In Code 1 we can reuse the same Cache Line for a while, depending on the size of each Array Element. But not in Code 2!
Thus, make it a habbit to sort your loops! It's easy to do! If the above example doesn't seem to make a difference on your Compiler, the reason is probably that your Compiler probably optimized it. But it usually can only do that in very special cases, where nothing happens in the outer loop!
Our 1.5 lesson
Say we have some huge Array of classes or structs that each are 65 Bytes in size. We now already know, that a single element won't fit into a one Cache-Line when we load it. As a matter of fact, it uses up 2! This could mean, we would potentially kick out 2 entire Cache-Lines.
It would be best if we were to redesign our class / struct to reduce the size by 1 Byte!
OR, we could think about other things we might add in that struct / class, but didn't include out of fear of bloating. After all, we might have 63 Bytes of otherwise wasted Cache-Line at our disposal.
Our second lesson
We learned that Cache-Lines are read in 64-Byte intervals and stored as such in 64-Byte offsets on the RAM. How do we even ensure, that our Array-Elements are even stored inside these offsets? The could span 2 Cache-Lines, even though they fit the 64-Bytes?
To be honest, there is no sure way of knowing this in most Languages. But I did mention earlier, that due to the fact that we have 64-Byte offsets, the last few Bits in the Address are always 0 at the start of a new Cache-Line in Memory. In Languages where we can explicitly look at the actual address of a variable, we can align our Data.
Let's take a look at a C++ example and I'll try to explain it in plain english in the Comments (or skip it altogether).
// A union allows us to access the same data location using
// different access methods. In this case, a pointe called dataPointer
// and a plain Number representation of that Pointer (i.e. it's address) called
// PointerAddress. Just in case, we should make sure that the data Type used
// for PointerAddress is the same size as the Pointer. 32-Bit on a 32-Bit machine, therefore
// we can get away with an int.
union
{
char * dataPointer;
int PointerAddress;
} dataBuffer;
// We create a temporary pointer to a newly created big chunk of Memory
// And add a bit of padding (63).
char* tempDataBuffer = new char[1000 + 63];
// We now assign our allocated space to our actual dataBuffer, but add an offset
// to the Pointer of 63. This means, we still have 63 Bytes of data available to us "in
// front" of the dataBuffer
dataBuffer.dataPointer = tempDataBuffer + 63;
// Now, by using our Union, we can directly access our Address as an int.
// We want to set the last few address bits to 0, in order to align it to 64-Bytes.
// We do this by inverting 64, which according to integer arithmetic gives us
// a Bit-Mask that does exactly that.
dataBuffer.PointerAddress = dataBuffer.PointerAddress & (- (int) 64);
// By Bit-Masking our PointerAddress, we shifted the entire pointer
// by 0 or up to 63 Bytes to the "front". Which is okay, as we added 63 Bytes of
// Padding "in front". Now, dataBuffer is 64 Byte Aligned.
Obviously, we can replace 64 by any other Cache-Line size.
The above code is probably best situated inside the Memory Manager, as it defines where our Memory should go. But back then, we didn't even know what the Cache was.
Multi-Core Processors
Now, let's take a look at something that can't be ignored by Programmers anymore: Parallel Programming.
The biggest Problem we will face for now when thinking about Parallel Programming is, what happens when 2 Cores decide to work on the same Memory?
The 2 Cores don't even need to work on the exact same Memory Location, the Memory locations just need to be on the same Cache-Line for our Problem to arise.
As we've discussed, L1 Cache is local to the Core. This means, each Core will have it's own copy of the same Cache-Line. Now, if one of the Cores were to change the value on the Cache, the other Core wouldn't even notice this and work on the wrong Memory.
Rest assured, that our CPU's know how to handle this. This entire phenomen is known as Cache-coherence. The implementation might differ from CPU to CPU, but in General, when a Core does something on a Cache-Line that is present in multiple Caches, a short exchange between the Caches take place to ensure everyone is working on the same piece of information.
What we need to know about this is, that this short exchange takes time. In our example, the 2 Cores were working on the same Cache-Line, yet on totally different Locations inside that line. This means, that the exchange between the Cache's wouldn't even be necessary, yet it still takes place and stalls our Core's. This is known as false-sharing.
Our third-ish lesson
This is a rather small thing to take away, as it doesn't occur as often. But i think it demonstrates a very interesting point - Having big Data Structures is not necessarily a bad thing.
Why? Let's look at an example:
Let's assume we have some Array of 32-Byte sized objects. This is all fine and dandy in regards to our first 2 lessons.
We now load parts of that Array into our Cache and start to work on it. We belong to the cool kids, so we do parallel Programming. Core 1 works on all the even elements of the Array and Core 2 works on all the uneven elements.
But somehow, our implementation runs slower than a single Core implementation? Why is that? Parallel Programming is supposed to heal all speed related issues?
We know what happened. Each of our 64-Byte Cache-Lines is actually filled with two 32-Byte Array Elements. And as it happens, one is an even Array Element, one is an odd Array Element. So each time one of the Cores is working on the Cache, it has to check with the other Core. That's alot of false-sharing going on right there!
A Data-Structure-way of solving this problem could concist of many ways. But the easiest one would be, we simply bloat the 32-Byte Array Elements to be 64-Bytes by adding some useless Data / Padding. Suddenly, each Element lives on it's own Cache-Line. Problem solved!-ish
Our fourth lesson
We've seen how padding can be used to our advantage, but how is it done correctly?
Let's take a look at a simple struct in C or C++:
struct someStruct
{
int someInt;
char someChar;
float someFloat;
};
What is the size of this struct in Bytes?
You might start by simply adding up the individual sizes of the variables. So, 4 Bytes for an int, 1 Byte for a char and 4 Bytes for a float. Which means, we end up with 9 Bytes, right?
Nope. It's actually 12 Bytes. Full 32-Bit variables live are 32-Bit aligned, meaning, they live on 32-Bit Memory boundaries (Assuming a 32-Bit System). They aren't usually split. You could, but you probably shouldn't. Thus our Memory might look like this:
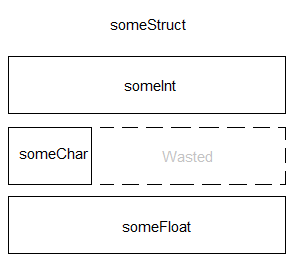
So, this would be equivalent to this struct
struct someStruct2
{
int someInt;
char someChar;
char padding[3];
float someFloat;
};
We practically wasted 3 entire Bytes! We shouldn't do that, unless we are doing something funky as in lesson 3. It is thus a good practice to sort your variables inside a struct from large to small. Keeping this in mind will allow you stop wasting space!
Locality, Locality, Locality
There are a lot more topics to cover when it comes to Cache and general Optimization. We will cover those in a future Part on actual Optimization. For now, let's stick to what we've learned and apply it to our Data Structures.
Back in our Card Deck example, we decided to go with a List that lives in a compact Memory Pool. We now immediately see the benefit of compactifying the area the List lives on: spatial locality!
We request to load 1 Card into the Cache and the entire Cache-Line will be filled with other Cards. Now, these other cards might (best-case) or might not (worst-case) be of interest to us in the near future.
This is of course better than a fully fragmented Memory where each Card lives at some arbitrary location on the RAM, and each Cache-Line is polluted with useless Memory (definite worst-case).
This knowledge will allow us to design our Data Structures better and optimize our Memory Allocators!
Another look at Lists
Our List seems pretty good thusfar. We have a certain probability that each element might live near another element we might need in the future. For our Card Game, if the Deck is ordered, this is the best-case scenario. Our linked List will probably reference elements that are right next to each other in Memory, pretty much like a simple Stack. Looking Good!
But we can do a bit better! What happens if we shuffle parts of the deck? Those individual Cards in our List will still live in the same Memory region, but might reference a Card that is far away inside the Pool.
Now we shuffle again and it gets worse and worse.
The obvious answer should be sorting. We can sort our List (in Memory!), so that Elements that reference each other live nearby. Suddenly we get our spatial locality back and all is good!
Why didn't we just use a Stack in the first place then, if we are going to sort anyways?
Sorting takes time. Having to sort each time something happens to our Card Deck could be a bad idea.
By implementing our linked List with a sorting Algorithm, we can decide when to sort. We have some downtime rendering a Frame? Let's sort the List. We notice a conciderable loss in speed? Let's sort the List.
Knowing that we might need to do this in the future allows us to structure our Engine in such a way to actually allow this to happen.
Enough of this Cache.
This Part has been rather long, let's stop here for now. There are alot of details we left out, but I think this should be enough to get an overview of the general concept.
In a future Article on actual (post-) Optimization, we will talk about more subtle aspects to Cache/Memory related Programming, like Load-Hit-Stores and a completely different world of Caches: the Instruction Cache. Woah.
I'm currently working on a Game using alot of these Methods, so feel free to contact me via Twitter @Spellwrath or leave a comment below.
Read more about:
Featured BlogsYou May Also Like





