




Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
Early user churn can destroy even the best games. Here’s how Nordeus, makers of the most played online sports game in the world, Top Eleven, identified early churners and turned them into valuable daily players.

Churn is a widely known term in many industries, including banking, telecommunications and gaming.
When people think about churn, it is mostly about veteran or late churn, however, hardly anyone talks about early churn.
In gaming, there are many definitions of early churn depending on the game or genre, but a general definition is that an early churner is a user who comes into your game, plays the game for a short period of time, and then leaves the game, never to return again.
If early churn is reduced, retention rates are increased alongside all other metrics – if a user plays your game more often, the chances that the user invites their friends to the game or makes in-game purchases are much higher.
In gaming, the early churn issue is usually addressed by creating a good tutorial or by optimizing the first few levels of the game. To address early churn further, many teams create and develop a new in-game feature.
Depending on your game and the magnitude of the feature, actual implementation of it can take ages.
But, what if there’s something that we, as data scientists, can do to reduce early churn without burdening the product team with new features to create?
This was exactly the question that sparked our effort at Nordeus towards identifying early churners in our flagship game – Top Eleven.
Top Eleven is a social online cross platform free to play football manager game with over 120 million registered players. When a player registers, they are given a football club with the aim of building it to be the best in the world.
They can play around with team tactics, train their players, sell and buy new ones and, of course, play matches. There are 3 competitions per season – League, Champions League and Cup – while the season itself lasts just 28 days.
We wanted to tackle the issue by identifying early churners as quickly as possible, and then targeting them with some kind of personalized push notifications.
So, how did we predict early churn? It turned out to be more of a question of when rather than how.
Depending on your particular use case for early churn prediction and your game in general, you may want to engage a prediction algorithm sooner or later.
When we started our early churn prediction in Top Eleven, we knew we wanted to do reactivation using personalized push notifications, but we still couldn’t figure out when exactly we want to predict. So what do you do when you’re not sure about something? You test!
We made 3 slightly different models, predicting for 3 days, 2 days and 1 day after user registration.
After the prediction, we send out a non-personalized push notification that invites the user to reactivate, just to get a proof of concept. Here are the results.
The 3 day model gave us the best accuracy, but we were not satisfied with the reactivation rate.
The 2 day model managed to retain the accuracy of the 3 day model, however we were still not completely satisfied with the reactivation rate.
The 1 day model achieved lower accuracy than the 2 aforementioned models, but we finally saw an improvement in reactivation we wanted from the start.
We then decided to focus our attention on the 1 day model and try to optimize it as much as we could, before continuing to the targeting phase.
Regarding feature selection for the models, well, if you're trying to predict something with just one day of data, like we did, you should really use everything you’ve got.
We first focused on users' registration information, hoping to use the quality of the registration source as one of the predictors. We collected the users' registration platform, country, UTM code and if they had registered with Top Eleven before.
We also looked at our activity data, where we measure the users' sessions, their length and intervals between two sessions, trying to get a sense of users’ immersion.
Included in our data were in-game currency actions, to measure how many boosters the user spent and bought.
The models worked ok with these features, but ultimately we ended up adding more complexity.
What really changed the accuracy and gave it a significant boost was taking advantage of our event data collection and adding user clicks as features. Group all the user clicks by certain features in the game, we were able to understand the users' most and least favourite features of Top Eleven.
This, with the addition of some Top Eleven specific features that we knew from before correlated well with churn, produced models that we were finally happy with.
Our top three performers after extensive hyperparameter optimization were Gradient Boosting trees, Logistic regression and SVM.

In the end we chose to use logistic regression in production because it is easier to maintain and more scalable.
Going deeper into the model’s performance, in terms of precision and recall, we aimed at achieving the highest recall possible for the positive class - churners. In the end we settled for 0.85 recall, 0.7 precision for the positive class and 0.5 recall, 0.7 precision for the negative one.
Relatively poor performance for the negative class is easily mitigated by sending push notifications around the time of user registration the day before. This little trick takes care of the false positives and improves our accuracy even more.
Being able to effectively identify early churners is one thing but getting them back is the real problem.
Push notifications are the obvious medium to use in this effort; however, there is a thin line between a good push notification and spam.
With a myriad of applications bombarding users with messages these days, patience is in short supply.
The goal is to make the notification as useful as possible, transfer some information with it to the user and make it actionable.
We framed our Top Eleven reactivation efforts with this in mind and approached the problem carefully, but with only one days’ worth of data to go on, constructing the right message would be a challenge.
After days and days of brainstorming it turned out the answer was in front of us the whole time.
Remember those grouped user clicks we used for the prediction? We can actually use them to create personalized messages. Take a look at this graph:

Here the vertical lines represent various features in Top Eleven and the coloured lines represent different types of users. The orange guys clearly like Squad and Training, while the red guys, for example, like the League feature the most.
If we start with two assumptions - people will churn because they find the game overwhelming and they will certainly remember the most used feature, we can use this information to tailor user specific messages, explaining them the feature further.
Consider these two examples:

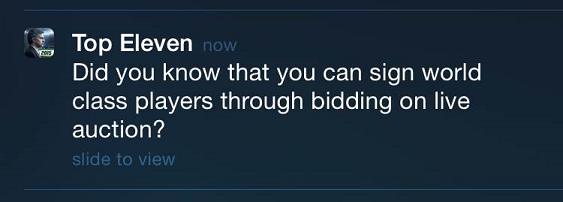
These notifications clarify Training and Auction features in Top Eleven, respectively. They also sound inviting, and are actually deep linked to their corresponding feature, so when a user clicks on them, they are automatically placed in the appropriate scene in the game.
Now that we know how to predict and target early churners, all that's left is learning how to measure the results correctly.
To differentiate between two different notifications we found it's best to measure click through rates. However if you want to know the general effect of your targeting effort, it is best to measure retention.
To achieve this, you need to split your user base into 3 groups: control, baseline and test.
Some might wonder why 3 groups and not the typical control/test split. The problem with using only two groups is you won’t know what is making the difference, the push notification or its content.
The solution we implemented was that the baseline group receives an unpersonalized general notification, while the test group receives the targeted one.
Finally, let me guide you through our results using this approach.
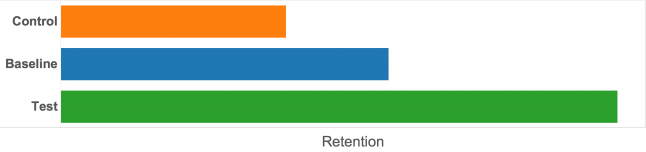
As you quickly notice, we achieved significantly better results with baseline group, and then with the test group. Our baseline group achieved 30% better retention than the control group, and the test group had a 40% improvement over the baseline group.
However, these results didn’t come to us instantaniously. Even though we had acceptable results when we first started, we had to iterate over many different messages to find the right set of words and tone to finally get where we are now.
I hope you enjoyed this article and had as much fun as myself when writing it. It will be my pleasure to share our experiences and knowledge in the future.
I'd also like to send out a special thanks to the team – Igor Anđelković, Nenad Živić and Marija Beslać.
Read more about:
Featured BlogsYou May Also Like





