


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Deep learning has revolutionized the video game industry by processing complex data patterns.

Deep learning has revolutionized the video game industry by processing complex data patterns. It enhances graphics, AI, and personalization in game development. With realistic visuals, adaptive NPCs, and procedurally generated content, deep learning pushes the boundaries of gaming. As it continues to evolve, deep learning promises more immersive gaming experiences, shaping the future of the industry.
One area that has been researched intensely is procedural terrain generation using deep learning. Previous research in this domain made some great steps to develop models with the purpose of generating realistic terrains, but has also stated that there is room for improvement for these models. I took on the role to try to improve on these models.
Previous studies made use of Generative Adversarial Networks (GANs) to generate the terrains. A GAN is a deep learning method where two deep learning models are trained, specifically a generator and a discriminator. Training works by making the generator generate a batch of samples based on random input vectors. This batch of “fake” samples is then mixed with real samples and provided to the discriminator. The discriminator hereafter tries to classify whether each sample is real or fake. Both models are updated afterwards, with the discriminator trying to discriminate better, and the generator trying to generate more real-looking samples.
While doing my literature research, I came across two papers that described a common problem, these were studies done by Beckham and Pal in 2017, and Panagiotou and Charou in 2020. These studies used two different GANs to generate two parts of a terrain: one generating the texture, and the other generating the heightmap. Both papers stated that by combining the scopes of these GANs into one single GAN, the results could be more robust and realistic. Panagiotou and Charou also noted that this would require a more complex model, and therefore would have trouble converging, i.e. it would have trouble improving during training. This is why I decided to evaluate and compare the new GAN I was going to develop on both realism and convergence. On top of that, I also wanted to compare some other GAN properties, which is why I also wanted to evaluate training time and computational performance.
In order to train and generate a terrain using a single model, I was looking for an already existing deep learning architecture that is able to achieve this. After some digging around, I came across the StyleGAN2 architecture, an architecture introduced by Nvidia. The StyleGAN2 architecture has been proven to work successfully on the generation of human faces, a perfect example of that being thispersondoesnotexist.com, a website which makes use of StyleGAN2. With an adapted version of StyleGAN2, this might also work with the generation of terrains. Luckily, an adapted version of StyleGAN2 that matched this description already existed, thanks to Diego Porres (https://github.com/PDillis/stylegan3-fun).
This adapted version works on four channels instead of the usual three-colour channels a GAN usually works with. This is because the model also generates a heightmap for the terrain at the same time, which requires this fourth channel. I promptly named the model SingleTerrainGAN, because it only uses a single GAN to generate terrains as compared to the models developed by previous studies. I trained SingleTerrainGAN on two datasets used in previous studies, those being the studies done by Beckham and Pal and Panagiotou and Charou. SingleTerrainGAN was trained on 5.000 k-imgs, meaning it has been trained on a total of 5.000.000 images. This turned out to be more than enough images to get good results.
While checking the output of the GAN after training, I noticed that terrains had a lot of noise when rendering them as a 3D model. This is why I decided on adding a box blur with a box blur to counteract this.

I now had a working GAN that produced realistic-looking results!

To see whether the trained SingleTerrainGAN indeed generates more realistic-looking terrain than models introduced in earlier studies, I set up a survey that compares terrains generated by an earlier model with terrains generated by SingleTerrainGAN. The participants in this survey had to select which terrain they perceived to be more realistic in terms of visual appearance.
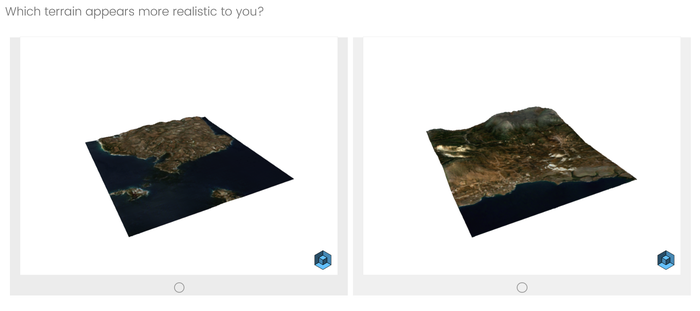
The survey got favourable results for SingleTerrainGAN, as terrains generated by SingleTerrainGAN were chosen more often than terrains chosen by earlier models.
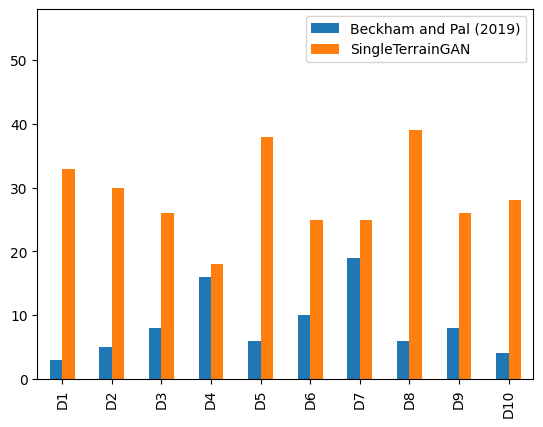
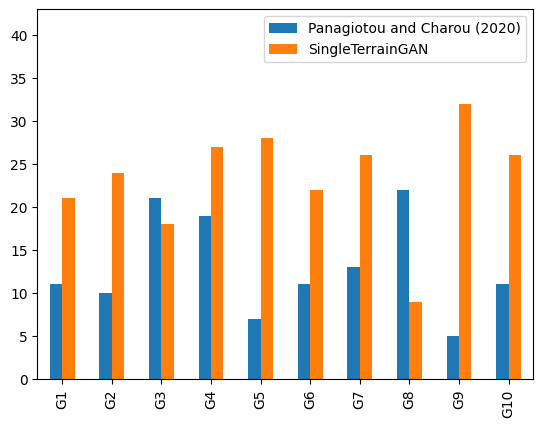
Another metric I used to evaluate whether SingleTerrainGAN generates more realistic-looking terrain is by looking at the Fréchet Inception Distance (FID). This metric can test how similar a generated dataset is to its trained dataset and is frequently used to evaluate GANs.
Usually, in the case of deep learning models, convergence can be evaluated by plotting the loss over the training course in a graph, and seeing how it progresses over time. Unfortunately, this doesn't work for GANs, as this would require me to plot two different losses which go up and down irregularly, meaning evaluating convergence this way would be a lot harder. Instead, I re-used the Fréchet Inception Distance that I also use for evaluating realism and calculating this score for intermediate models I got during training. This still allowed me to see how the training progressed in terms of convergence.
Doing this for each GAN, I saw that on top of the FID being much lower than earlier models, SingleTerrainGAN also converged much faster than earlier models.
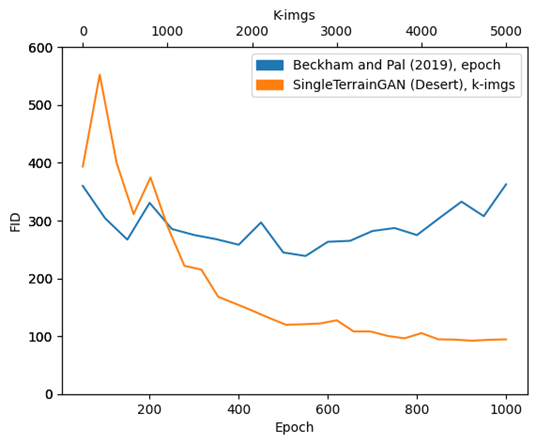
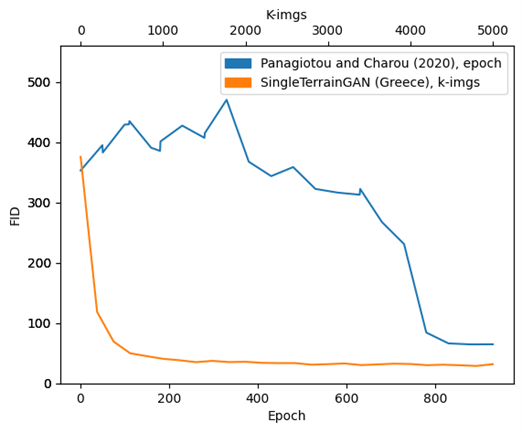
This also means that by looking at the survey results and the FID score of SingleTerrainGAN, it is evident that SingleTerrainGAN produces more realistic-looking results compared to earlier models.
Training time, generation time and memory footprint are other metrics that were compared. I measured training time by just tracking the time during training. To measure generation time, I let each GAN generate 50.000 terrains and calculated the mean of the total generation time to get the mean generation time of a single terrain. The memory footprint was measured using the NVIDIA System Management Interface (nvidia-smi), for which you can easily check how much GPU memory is used during generation.
SingleTerrainGAN proved that in terms of training time, it took longer to train, or trained in a similar timeframe compared to earlier models. Generating now takes approximately 13 milliseconds for the GAN trained on the Greece dataset, and 18 milliseconds for the GAN trained on the desert dataset, which is a decrease of 2 milliseconds compared to earlier models. The memory footprint is a huge difference, with SingleTerrainGAN using up to almost 15 GB VRAM less than earlier models.
For a full view of the survey data, and the models that were used during the survey, you can view my GitHub repository (https://github.com/LarsSluijter/SingleTerrainGAN). This repository also includes a download link to the models that were used to generate the terrains, so you can try it out for yourself!
Read more about:
BlogsYou May Also Like





