




Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
Featured Blog | This community-written post highlights the best of what the game industry has to offer. Read more like it on the Game Developer Blogs or learn how to Submit Your Own Blog Post
A look at how Plumbee improved the processing of events from its gaming platform by adding a preprocessing step.

At Plumbee we value constant improvement: even if something works, we keep asking how it can be done better. Previously, we discussed how we use Apache Flume NG to read analytics events from SQS, partition them and finally store them in S3. In this blog post we will analyse how we separated the responsibilities and improved our data processing by introducing a preprocessing step.
Motivation
In the previous architecture, Flume was processing the events in a custom interceptor, mainly to partition them by event type (the reasons we want to partition events are explained here). However, collecting events from a variety of sources resulted in a very complex interceptor: it had to deserialise the event, inspect the relevant fields to determine the event type, and handle malformed events. While the performance penalty was not significant, understanding the flow of events from SQS to S3 was not trivial and it was easier to make a mistake.
Another drawback was that low-volume events, such as level-ups, were not transferred to S3 with the same frequency as high-volume events, leaving them in an EBS volume for longer - which complicated the recovery in case of a Flume failure. We could have countered that by uploading everything to S3 every hour, but then Flume would have been creating too many small files, reducing the performance of the following map-reduce jobs to a crawl.
Finally, a lot of our map-reduce jobs aggregate events at the user level and reconstruct the timeline of the user's activity. Therefore, it would be very beneficial if we were to group and order the events in advance, to avoid doing it multiple times, and to use map-side aggregations to minimise the volume of data that moves from the mappers to the reducers. However, we could not implement that, as Flume was processing the events in real time.
Implementing the preprocessing step
As mentioned above, Flume used to categorise the events using a custom interceptor. To implement the preprocessing step we had to change Flume to write everything in one file and move the categorisation logic in a separate map-reduce job that would read Flume’s output and partition it.
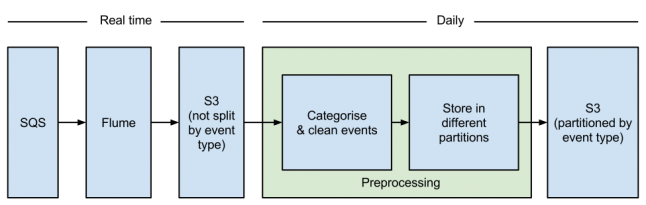
It was fairly straightforward to extract the functionality from the interceptor, which used the chain of responsibility pattern to add the event type to every event. This reduced the lines of code in our Flume codebase by 20%. Writing everything in one file was also easy and simplified Flume’s configuration.
Perhaps surprisingly, the biggest challenge we faced in writing the new map-reduce job was having the output written to different files based on the event type.
First, we tried emitting the event type as part of the output key. Each output key is processed by only one reducer which means that the output file will only have one event type:
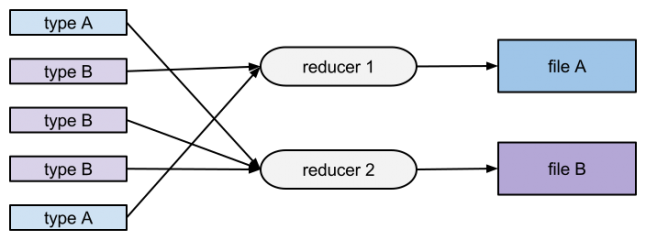
This would be viable for a uniform event distribution; ours, however, is heavily skewed: 95% of our data volume is generated by 20 event types and the remaining 5% by 225 types. Therefore, the resulting map-reduce job was too slow for our data.
The next approach was to modify the reducer to write to multiple output files based on the event type, removing the event type from the output key:

This solved the performance problem as the events were distributed evenly across the reducers. However, each reducer created a different file for each event, resulting in over 5,000 small files that would slow down the following map-reduce jobs.
At this point, we decided that we had to change the way events are distributed to the reducers. In Hadoop, this is the responsibility of the partitioner. Usually, the partitioner calculates the hash of the output key and maps it to a reducer based on the total number of reducers:
abs(object.hashCode()) % totalNumReducers
It is possible to provide a custom implementation for the partitioner. For our case, we wanted to send events of the same type to as few reducers as possible, yet distribute the load evenly.
We achieved that by having rare events share the same reducer while sending the more frequent events to multiple reducers:
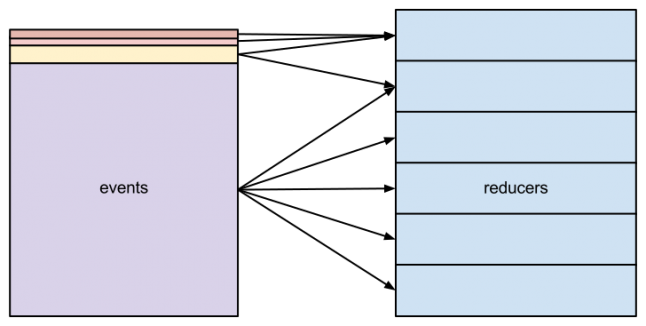
In the current implementation, we use data from previous runs to predict the distribution of new events. As the distribution is stable, a naïve approach of assuming that it is the same as the previous day’s is sufficient. An alternative approach would be to use a moving average of the last seven days, but it is not necessary in our case.
After finding the expected volume per event type, the algorithm calculates the number of reducers to allocate to each event, which can be fractional for small events, and the offset, which is used to avoid reducer overlap. This is stored in a map which is serialised and passed to the partitioner as part of the job configuration. Then, the partitioner uses it to assign the reducer based on the hash of the output key:
abs(object.hashCode()) % totalNumReducersForThisEvent + offsetForThisEvent
A few reducers are not assigned to events from the previous day in order to handle new event types. While this leads to some underutilisation of reducers, the performance is reasonable and the small files are kept to a minimum. Another optimisation is to sort the event types by total volume, which reduces the file splits even more, as the low-volume events are grouped in a few reducers. Overall, this solution allows us to run the preprocessing step on our daily data (166GB compressed) in about 30 minutes, using 45 m3.xlarge nodes and outputting 600 files (about 2.5 files per event type).
The main problem we anticipated was performance. Indeed, the preprocessing step is the longest task in our daily ETL, taking about 25% of the total time, during which we cannot run anything else. However, we think it is worth it: we achieve higher compression rates (up to 50% improvement for repetitive events where ordering by time allows efficient run-length encoding) which decreases the time wasted in I/O. It also enables us to use map-side aggregations (combiners in Hadoop or partial aggregations in Cascading) which, according to what we’ve tested so far, improves performance from 30% to 60% depending on the type of the aggregation.
However, the main benefit we see is the improvement of our architecture. Before the introduction of the preprocessing step, we had to clean the data while processing them, resulting in unnecessarily complicated map-reduce tasks that often had guards for edge cases all over the code and fixed the same problem again and again. With the preprocessing step, we can fix malformed events in one place and do it only once as everything else reads the clean data. This is especially useful if we need to apply a transformation to fix a problem that only affected data for one day, as it is not necessary to keep the fix for future runs that work with the problematic data set.
Finally, partitioning is decoupled from Flume: we can change the partitioning logic without redeploying it (which disrupts, albeit minimally, the real-time consumption of events from SQS). We can also re-partition old events without having to extract the logic from the interceptor (or worse, having to replay the events so that Flume can categorise them).
Conclusion
Similar to writing a compiler, it is often tempting to try to do everything in one pass. It may seem counter-intuitive to expect a performance improvement from parsing the data multiple times, yet, depending on the structure, there can be one. Multiple passes allow several types of optimisations and, more importantly, make it easier to write clean, maintainable and bug-free code. In the future, we plan to introduce additional cleanup steps in the preprocessor, further reducing the complexity of the actual data-processing tasks, and to add more map-side aggregations to improve performance.
Read more about:
Featured BlogsYou May Also Like





