






Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
While trying to work with sorted sets I've discovered some interesting things about dotnet core performance, but am at a loss to explain all of them.

I've recently become a bit obsessed for no good reason with different implementations for sorted sets in C#. I was looking into different ways to squeeze more performance out of a chunk of code and discovered to my confusion that, in my particular circumstances, I was able to provide a faster one than any out of the box. I'm not that much of an algorithmic badass, so there must be something going on I don't understand. So I decided to do some quick-and-dirty testing of various possibilities.
There's a few things we can do if we find ourselves needing a high-performance sorted set:
We can use the SortedSet<> class. Probably a good call, after all, what are the odds that we're going to be able to write an implementation that beats the pros?
That said, since SortedSet<> uses a binary tree for its implementation (presumably, it's actually not that well documented afaict) it's possible for smaller n's that some kind of implementation built on a List<> would be faster. Unlike SortedDictionary<> which has its SortedList<> equivalent, there is no List equivalent for a Set. But, hey, we can use SortedList, and for a key use whatever we wanted to sort the elements of the set on in the first place.
We can do the same thing with a SortedDictionary as well - that's probably not going to be faster than SortedSet, but there are no guarantees in perf so I threw it into the mix just to see.
And I implemented my own quick-and-dirty List implementation of a Set, by BinarySearching into a List and inserting members myself. This has an instant advantage over the other sets in that with the other built-in C# sets I either have to check to see if the element is already in there before adding it, or put the Add in a try/catch block. With BinarySearch I could find the insertion point and tell if there's one already there at the same time.
There's an additional concern: should I use structs or classes for the elements in this set? Particularly with List-based implementations, cache-friendly structs might be just what the doctor ordered. Taking a look at Jackson Dunstan's example - https://jacksondunstan.com/articles/3860 - I was thinking that surely value based structs would be awesome! So l tried everything with both classes and structs and a variety of sample sizes to see what would happen.
In particular I was interested in the changeovers - at what sample size does it make sense to switch from a O(n) where the operation is dirt-cheap to O(log n) where it's not so much? Where does the cache friendliness of the array of structs start to mean less than having to move a large volume of those structs for each Insert?
So here are my results for the Insert. These are with test structures that contain 4 ints.
This may be hard to read at first but the upshot is that with n of around 5000 the SortedSet is the winner, but with an n of 2500 my hand-rolled binary insert wins; the break-even point is somewhere between 2500 and 5000. Which was kind of surprising to me: log2 of 4096 is 12; are you really telling me the 12 operations the SortedSet is doing on average comes out to about the same as the 4000 operations the BinaryInsert is doing? But since it's simply moving 4000 structs ahead a few bytes in memory I suppose it's not too hard to believe.
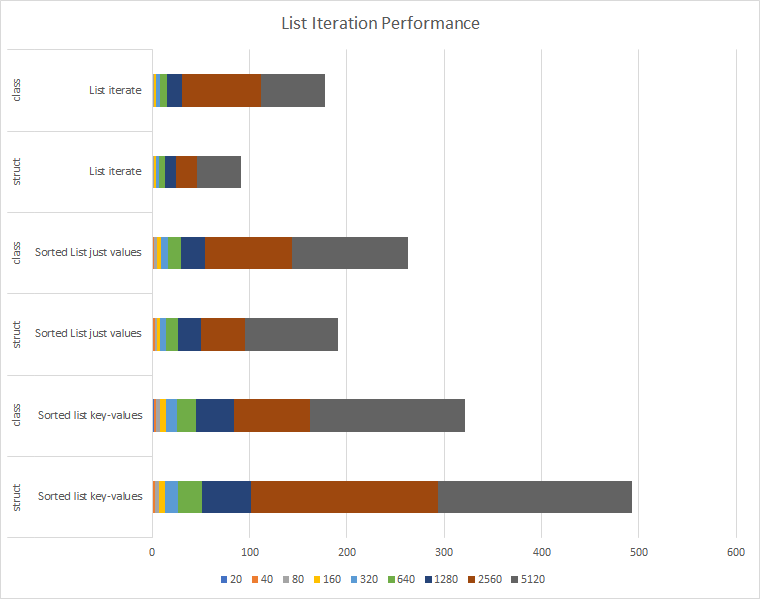
Here's something I didn't get, though, is what happened when I looked at iterating over these structures:
The list iteration is great, and the cache friendly struct version of the list is even better. I thought I'd see the SortedList performance in the ballpark of my List, though. After all, isn't it basically just a List? And why was the struct version of the SortedList so much slower than the class version? (It's hard to tell from the picture, but it's better with small n's, in the < 500 range, but then it falls off hard.)
I re-read the documentation (https://docs.microsoft.com/en-us/dotnet/api/system.collections.generic.sortedlist-2?view=netframework-4.8.) Hmm, it's a list of KeyValuePairs--is that making it less cache-friendly?--but according to the docs those are structs too. So, ok, it's doing an extra dereference. (I knew that, it's right there in the iterator code.) That'll take time. But that much time?
At this point I feel like I've spent too much time digging into this. I think about stepping through the code in the Visual Studio debugger to see what it's doing. Then I remember that dotnet core is open source. I can do something I've never done before; look at the source code of the language I'm using. Holy crap, there it is! https://github.com/dotnet/corefx/blob/master/src/System.Collections/src/System/Collections/Generic/SortedList.cs
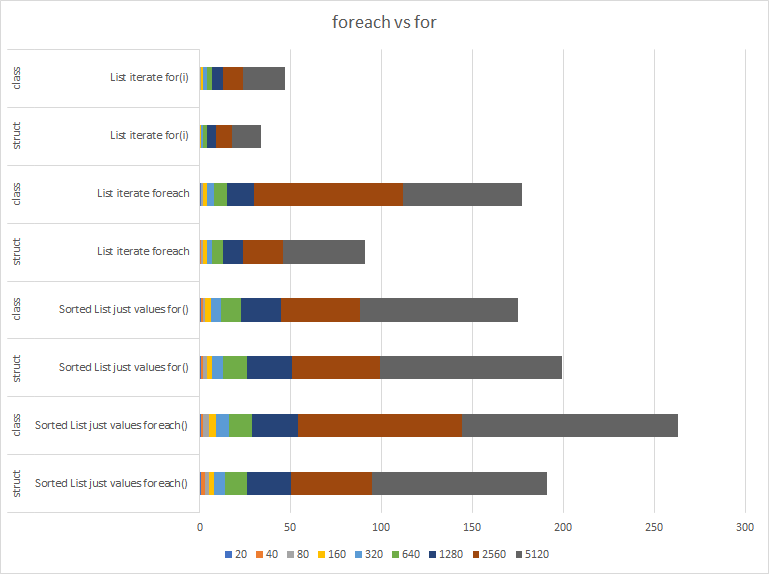
Ohhhhhhhhhhhhh. It is two lists, and when I iterate over it using foreach(), it has to create a KeyValuePair for me. In other words, I am doing it wrong; I should be iterating over just the values. Let's compare:
Huh. So when I iterate over just the values it is much better than iterating over the pairs as we'd expect, but it's still puzzling that it's that much slower than the vanilla list. At this point it should be identical. Back to puzzling over the code… I dig up the MoveNext for List<> and after looking back and forth between the MoveNext for the sorted list values and the MoveNext for List I couldn't tell you why one is slower than the other.
In the meantime, it seems like using an enumerator, which is just indexing into the list anyway, is doing extra work which good old for( int i … ) wouldn't do. So I gave that a whirl.
Yikes. I really wasn't expecting such a huge difference. I'm usually a 'premature optimization is the root of all evil' type but I might never use foreach again.
So my main take-home lessons from this experience are:
if performance is an issue, maybe reinventing the wheel can actually be a good thing
even if n is in the thousands O(n) might be better than O(log n)
foreach. yeesh.
This dive into C# performance turned out to be a rabbit hole - I'm not sure when we're going to hit bottom. For example, maybe I should now test it in Mono and Visual Studio to see if the same performance characteristics carry over. If I'd known how long this would take I might not have bothered, but it was a learning experience! But I'm going to pull myself away now and maybe see if I can learn something from y'all instead of digging in further myself.
What I really don't get is that now I'm indexing into the two different kinds of list myself, why is the one still so much slower than the other?
I throw it to you. Can you shed light on this for me?
I would be completely unsurprised (but still a little embarrassed) if there's just an obvious bug in the code. I've put it up to play with in github: https://github.com/JamieFristrom/SortedContainerTests
Read more about:
BlogsYou May Also Like





