


Trending
Opinion: How will Project 2025 impact game developers?
The Heritage Foundation's manifesto for the possible next administration could do great harm to many, including large portions of the game development community.
In this Intel-sponsored article, Orion Granatir explores two approaches for building a highly scalable 3D particle system: task-based threading and SSE. The good news: 3D particle systems are ideal candidates for multithreading even if you’re a novice.

Sponsored by Intel
[3D particle systems are an important part of gameplay. Whether it's flying debris after a massive explosion, flotsam and jetsam from a ship wreck, or Autumn leaves swirling in the wind, realistic 3D particles increase the immersive experience.
In this Intel-sponsored article, Orion Granatir explores two approaches for building a highly scalable 3D particle system: task-based threading and SSE. The good news: 3D particle systems are ideal candidates for multithreading even if you’re a novice.
Better yet, they can be scaled to look great on a wide spectrum of hardware, from the we're-so-envious high-end game machines to the hey-don't-judge-me-I'm-paid-for lower-end PCs.]

Particle systems are an ideal candidate for multi-threading in games. Most games have particle systems and their general nature of independent entities lends well to parallelism.
However, a naïve approach won’t load balance well on modern architectures. In this column, we explore two complementary approaches, task-based threading and SSE, which are ideally suited for particle systems that obtain maximum performance from multi-core processors.
A particle system is ideal for threading because it’s essentially a big loop that operates on a bunch of independent objects. Because the objects don’t need to interact (they don’t write to shared data), they can easily be spread across multiple threads.
Here is an example of a loop that updates all particles:
for( unsigned int i = 0; i < NumParticles; i++ )
{
UpdateForces( g_Particle[i], DeltaTime );
UpdateCollision( g_Particle[i], DeltaTime );
UpdatePosition( g_Particle[i], DeltaTime );
}
Threading these loops is trivial. OpenMP is supported by all major compilers and allows simple for-loops to be parallelized. OpenMP will automatically divide the loop and run it across all available cores on the machine.
#pragma omp parallel for
for( unsigned int i = 0; i < NumParticles; i++ )
{
UpdateForces( g_Particle[i], DeltaTime );
UpdateCollision( g_Particle[i], DeltaTime );
UpdatePosition( g_Particle[i], DeltaTime );
}
However, this is not an ideal approach. This method does not support good load balancing in a complex system such as a real game. For example, if spawned threads generate more threads (nested threading), then it’s possible to oversubscribe the system. Oversubscription causes a performance hit because there is an overhead associated with swapping the execution of the threads.
There is a better way to thread particles than the simple fork-and-join approach of OpenMP’s parallel for. It’s very simple to divide the work to run as tasks. Using tasks provides several benefits. Once you have a tasking system set up, it’s easier to add new tasks to increase parallelism throughout the code. Also, it’s easier to load balance and be platform-agnostic.
If the task scheduler manages all parallel tasks, the program will avoid oversubscription. In this example, we don’t have to wait for all the particles for a given emitter to finish before moving to the next emitter and scheduling more tasks.
To convert the loop above to use tasks, the code needs to divide the work into several tasks and submit them to a task scheduler. These tasks will define the range of particles to update and includes all required information.
unsigned int Start = 0;
unsigned int End = 0;
unsigned int ParticlesPerTask = NumParticles / NumTasks;
for( unsigned int i = 0; i < NumTasks; i++ )
{
// Determine the range of particles to update
// (the last task might be bigger)
End = (i < (NumTasks-1)) ? uStart + ParticlesPerTask : NumParticles;
// Build and submit the task
ParticleTask* pTask = &g_ParticleTasks[i];
pTask->m_DeltaTime = DeltaTime;
pTask->m_Start = Start;
pTask->m_End = End;
g_TaskScheduler->addTask(pTask);
// Move to the next set of particles
Start = End;
}
...
void ParticleTask::Run()
{
for( unsigned int i = m_Start; i < m_End; i++ )
{
UpdateForces( g_Particle[i], m_DeltaTime );
UpdateCollision( g_Particle[i], m_DeltaTime );
UpdatePosition( g_Particle[i], m_DeltaTime );
}
}
Tasking is a great way to get scaling with a particle system. However, it’s also important to make sure the code fully uses the CPU cores it is running on. Developers should consider using SIMD (single instruction, multiple data) with SSE instructions. For floating point, SSE instructions operate on 4 floating points in a single instruction. Obviously, this has the potential to increase throughput by up to 4x.
There are multiple ways to use SSE. For developers interested in maximum control, intrinsics are the best way to utilize SSE. Intrinsics are compiler specific functions that generate inlined highly efficient machine instructions. For developers targeting DirectX on PC or Xbox, the XNA Math library wraps the use of intrinsics in a library that already supports vectors and matrices.
There are a few things to keep in mind when use the XNA Math library. First, be careful accessing individual elements. Getting and setting elements inside an SSE vector isn’t free. It’s best to put data into XMVECTORS and keep it there as long as possible. Also, make sure you are using properly aligned data.
For a more in-depth discussion on cross-platform SIMD, check out Gustavo Oliveira’s well written article.
A lot of this article is based on the learnings from my cube-mate, Quentin Froemke (lovingly referred to as Q-Ball). Quentin created a tech sample called Ticker Tape to showcase some best know practices for creating a highly scalable particle system. To learn more about Ticker Tape, check out the associated article and download the source code.

Ticker Tape simulates the physics behavior of fluttering and tumbling. This simulation showcases an interesting and complex particle behavior. The performance benefits for utilizing multi-core and SSE are apparent in Ticker Tape:
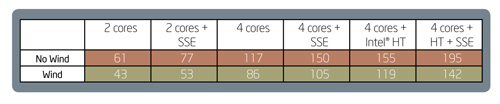
Both multi-core and SSE give significant benefits. The benefits of Intel® Hyper-Threading Technology are much more prevalent with SSE. Hyper-threading takes advantage of the fact that all execution units for a CPU core might not be fully utilized by a single thread.
Multiple execution units allow multiple instructions to be executed simultaneously and be pipelined. Execution units perform operations such as loads, stores, integer operations, floating-point operations, and SSE operations. With more SSE instructions, there is a better utilization of all the processors resources and therefore better use of hyper-threading.
If you are afraid that adding a highly parallel particle system will Duke Nuke your schedule, you can always investigate middleware options. For example, the team at Fork Particle has a parallel particle systems backed with solid content creation tools.
With higher core counts, it’s possible to scale with compute power and show a larger number of particles. This would give users a perceivable difference for high-end machines, without punishing players with lesser gaming hardware.
Particle systems are ideal for threading and a good wading pool for people new to threading. Future articles will go off the deep end and explore more complex problems like crowd simulation AI. In the meantime, check out Ticker Tape and let me know what you think!
You May Also Like





